The Multi-AI Thesis
LLMs confirm their own answers over 90% of the time and have a 64.5% blind spot rate on their own errors. Cross-family multi-AI pipelines — Claude reviewing GPT reviewing Qwen — break the self-review ceiling. The research, the costs, and what actually works.
AI-powered · Limited to 20 requests per hour
Every AI model has blind spots. A 2025 benchmark put a number on it: LLMs have an average 64.5% blind spot rate. They can't correct errors in their own output, but they can correct the same errors when presented as someone else's work. GPT-4 locates only 52.9% of reasoning errors in chain-of-thought traces, even straightforward ones.
This won't get patched in the next release. It's structural. Use one AI model to write code and the same model to review it, and your review process is partially theater.

The self-review problem
A 2025 study across 14 open-source models found that LLMs cannot reliably detect errors in their own output, but can detect the same errors when presented as someone else's work. The researchers traced this to training data: self-correction markers appear roughly once per 100 sentences in standard instruction datasets, compared to 30-170 times in reasoning model datasets. The models haven't seen enough examples of correcting themselves.
There's also a self-preference bias. Models assign lower perplexity (higher familiarity) to their own outputs and systematically rate them more favorably. RLHF training makes this worse by rewarding confident responses regardless of accuracy. But when the same content is evaluated in a fresh context, where the model doesn't know it generated the original, error detection improves significantly. Researchers call this the "clean room" effect.
A second opinion from the same model isn't really a second opinion. The model recognizes its own patterns and confirms them.
Same family is not multi-AI
I want to be clear about this distinction: running Claude Sonnet and Claude Opus on the same task is not multi-AI review. They share training data, architectural assumptions, and blind spots.
The echo chamber research backs this up. A 2025 study on multi-agent debate found that when agents share the same model and training data, debate "amplifies confidence in a wrong answer rather than correcting it." The paper calls this "belief entrenchment," where agents reinforce shared errors instead of catching them. The conformity is baked into the training. When one Claude instance says something is correct, another Claude instance is biased toward agreeing, because they learned from the same data.
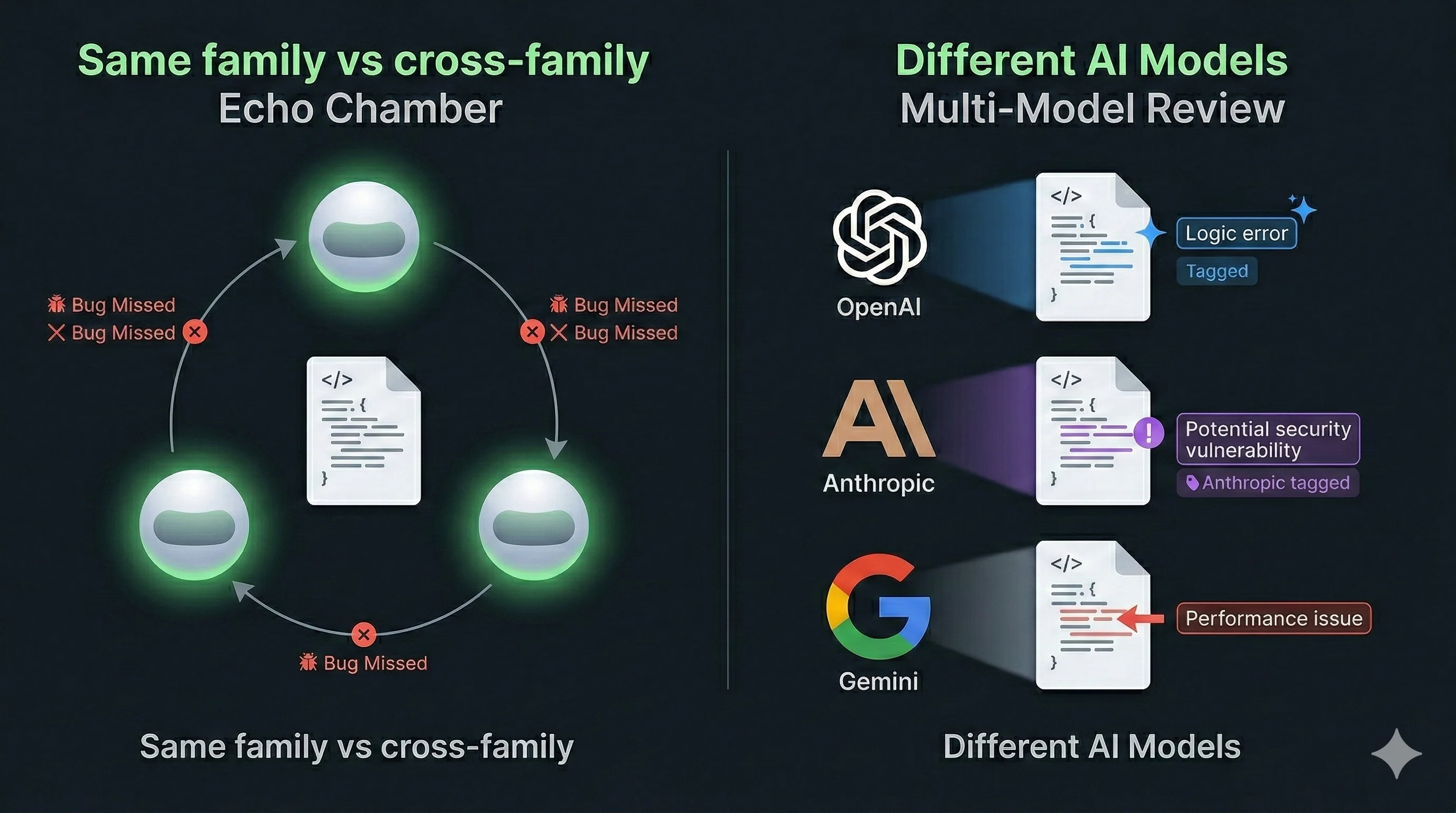
A separate study on multi-agent systems found two root causes for this: biased static initial beliefs (same training data → same starting assumptions) and homogenized debate dynamics that amplify the majority view regardless of correctness.
This is why I specifically mean cross-family when I say multi-AI. Claude reviewing GPT reviewing Qwen. Different training corpora, different architectures. The blind spots are far less likely to overlap.
What the research shows (and what I'm inferring)
The existing research strongly suggests that multi-agent systems outperform single agents in many settings. It does not yet prove that cross-family review specifically beats same-family multi-agent setups. That second part is my inference, but I think the echo chamber research makes it a strong one.
Blueprint2Code (2025) built a four-agent code generation pipeline (Previewing, Blueprint, Coding, Debugging) and hit 96.3% pass@1 on HumanEval. Single-model direct generation scored 84.7%. Removing any single agent degraded performance by 14.8-28.9%. The Debugging Agent mattered most: without it, accuracy dropped from 93.5% to 64.6%.
Anthropic's own multi-agent research system (lead Opus 4, sub-agents Sonnet 4, same family, worth noting) outperformed single-agent Opus 4 by 90.2%. Token usage explained 80% of the performance variance. Same-family multi-agent already beats single-agent. My argument is that cross-family should do better still, because you eliminate the shared blind spots that same-family setups keep.
Model Swarms (ICML 2025) applied particle swarm optimization to LLM experts and found that 56.9% of the best-performing final models came from the bottom half of the initial pool. Weaker models had latent capabilities that only surfaced through collaborative search. Human evaluators preferred swarm outputs over individual experts 70.8% of the time.
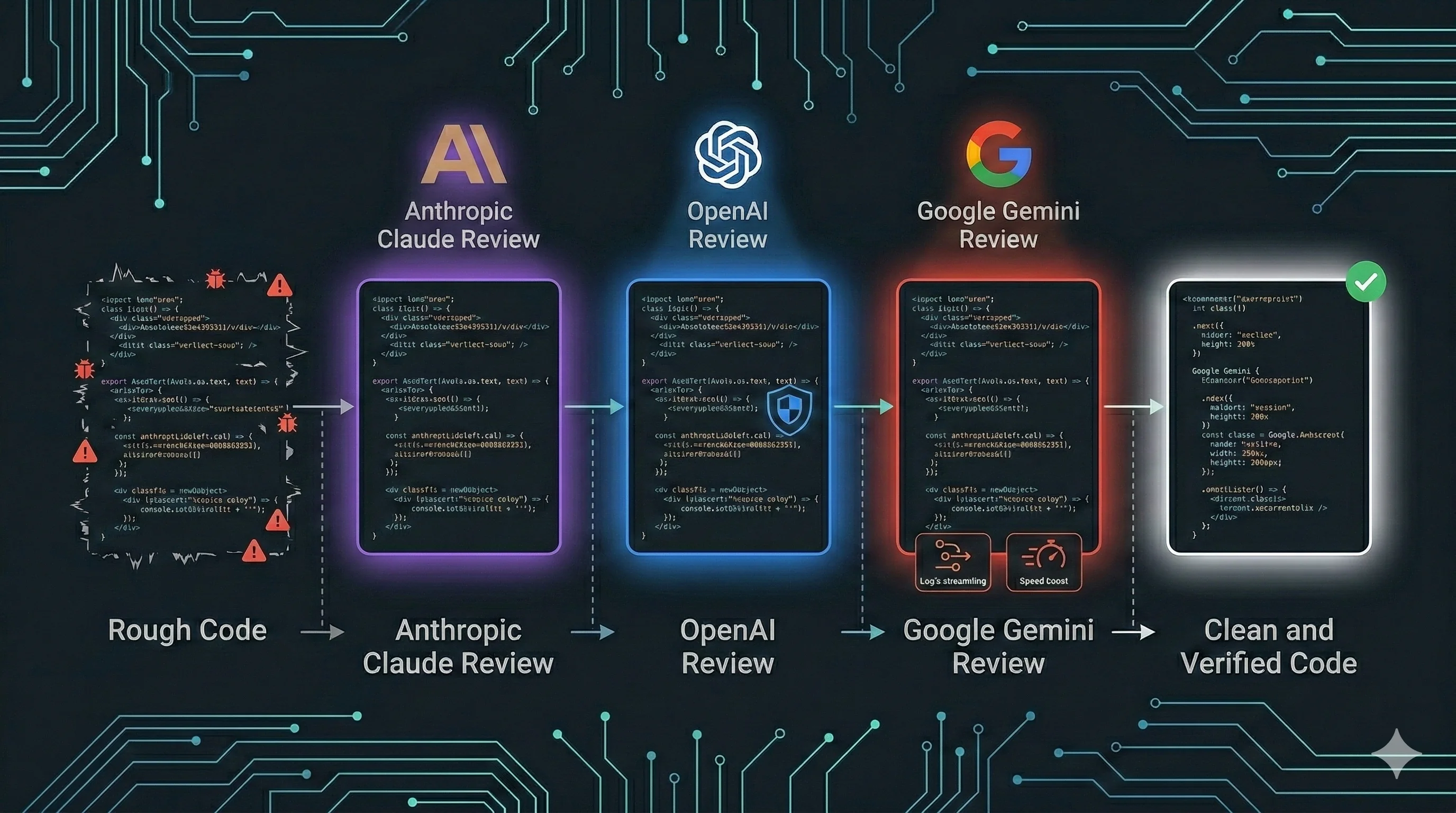
On the security side: 45% of AI-generated code contains security flaws across 100+ LLMs tested (Veracode 2025). AI code has 2.74x more XSS vulnerabilities and 1.91x more insecure object references than human code. RepoAudit, a multi-agent auditing system, detects true bugs in real projects at 78.43% precision.
The costs are real
Multi-AI is not free.
Multi-agent systems consume roughly 15x more tokens than single chat interactions. After accounting for inter-agent communication, retrieval overhead, and logging, the cost multiplier is 3-4x. One e-commerce company saw monthly LLM costs jump from $1,200 to $4,800 after enabling multi-agent workflows. Single agents respond 30-50% faster without the coordination overhead.
Industry surveys suggest broad interest in multi-agent systems, but scaling them is a different story. Tool calling accuracy, coordination complexity, state synchronization: the production problems are real. Most organizations that try multi-agent workflows struggle to move past the pilot stage.
Gartner reported a 1,445% surge in multi-agent system inquiries from Q1 2024 to Q2 2025. The demand is there. Making it work at scale is another thing entirely.
When single AI is the right call
Single-model workflows work better for narrow, well-defined tasks where the training data covers the domain. They're better for rapid prototyping where you need speed over correctness, and for cost-sensitive work where 3-4x token multiplication doesn't make sense.
Microsoft's decision framework says to start with a single agent when the domain is narrow, time-to-market matters, or the architecture decision is unclear. Prototype with one model, then add cross-family review when the stakes justify the cost.
A May 2025 paper makes an honest observation: "the benefits of multi-agent systems over single-agent systems diminish as LLM capabilities improve." As individual models get better, the gap narrows. Their hybrid approach, starting with a single agent and cascading to multi-agent only when needed, achieved 1.1-12% accuracy gains with up to 20% cost reduction over either approach alone.
What I actually do
In practice, I use cross-family review for anything that matters. Dev Buddy, a Claude Code plugin I built, runs code through pipelines where different stages can use different providers. Claude for implementation, Codex for a final review gate, MiniMax or Qwen for independent perspectives. Task dependencies make it impossible to skip stages, so the pipeline can't quietly drop a review step.
OpenHive, a project I'm building, goes further: hierarchical teams of AI agents from different providers, each running in isolated containers. Team leads decompose tasks and route to specialists. You can mix Claude, GPT, and Qwen agents in the same team.
The thesis
Single-AI workflows have a ceiling. The model confirms its own assumptions, misses its own blind spots, and rates its own output favorably because it trained on similar patterns.
Cross-family multi-AI raises that ceiling. Different training data means different assumptions, and different architectures mean different failure modes. What slips through one model has a better chance of getting caught by another.
It costs more and it's harder to orchestrate. For anything where correctness matters, it's worth it. 59% of developers already use three or more AI tools in parallel. The industry is headed here whether we have a thesis for it or not.
License
Article text © 2026 Mark Huang. Licensed under Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) unless otherwise noted. Article text is licensed for non-commercial sharing with attribution to the original article URL. Commercial use requires prior written permission and must clearly cite the original source.
Code snippets, screenshots, third-party assets, and site source code may have separate terms.
Suggested attribution: Based on "The Multi-AI Thesis" by Mark Huang, originally published at https://markhuang.ai/blog/the-multi-ai-thesis.
Related Articles

Don't You Think Your AI Is Too Optimistic?
RLHF can reward agreement over accuracy, turning AI into a source of sugar-coated bullets — validation that hides failure modes. How persistent adversarial rules change the default from flattery to honest challenge.
Read article
Why One AI Is Never Enough
Every high-stakes profession requires independent review — medicine, law, science, finance. AI is one of the few domains where people skip this step. 37% of enterprises already use 5+ models, but most do it ad-hoc. Chapter 1 of Cross-Family Multi-AI.
Read article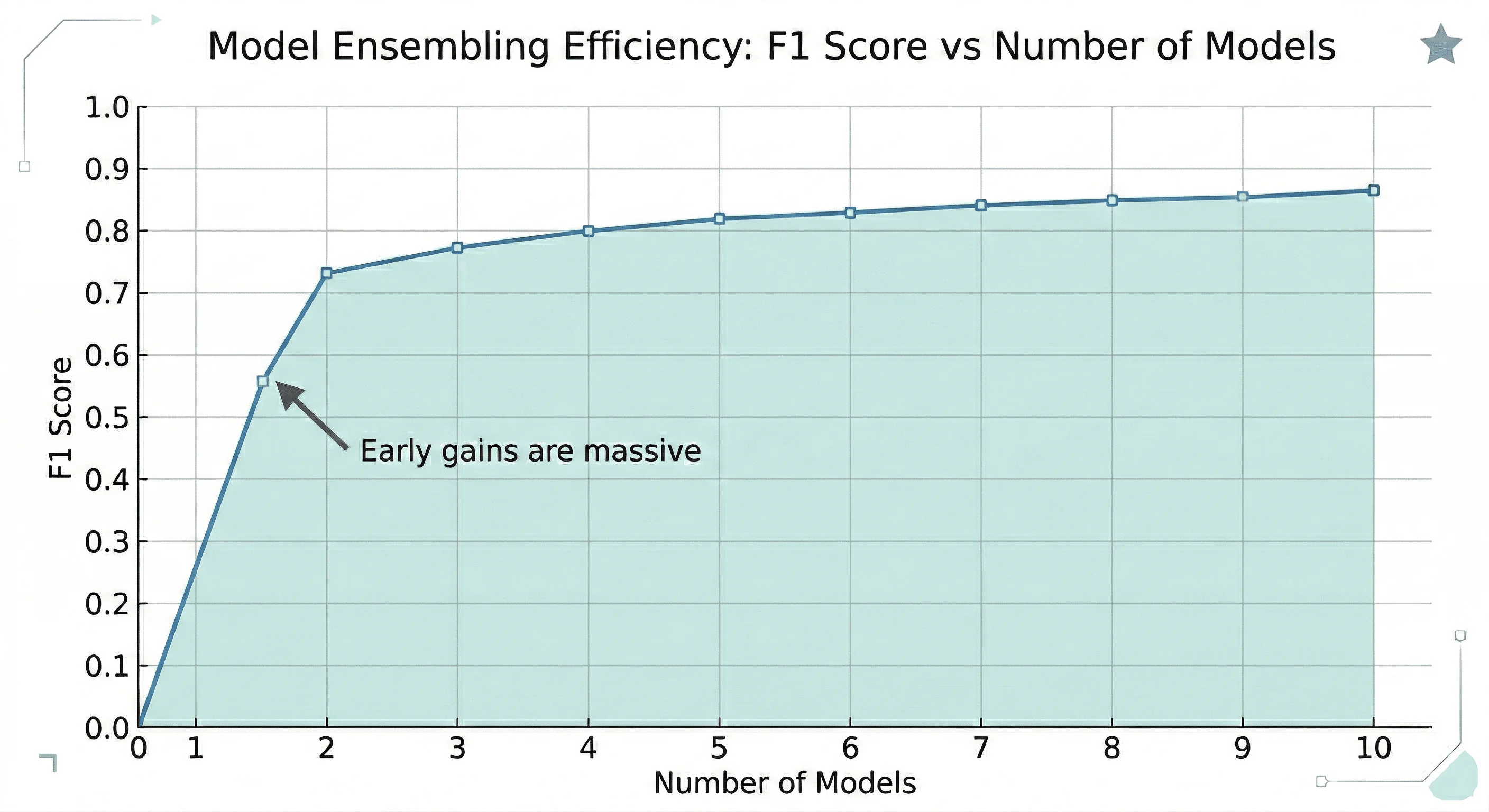
The Science of Ensemble Intelligence
Wisdom of crowds meets AI: diverse LLM ensembles outperform 67% of individual models, F1 scores jump from 0.55 to 0.80+, and 56.9% of best solutions come from the weakest models. The math behind cross-family multi-AI. Chapter 2 of Cross-Family Multi-AI.
Read article