Agent as Feature:当 AI 替代后端逻辑会发生什么
Gartner 预测到 2026 年,40% 的企业应用会嵌入 AI 智能体。Agent as Feature 模式用推理型智能体替代确定性控制器。本文探讨这对后端架构意味着什么,以及为什么这个潜力是真实的。
AI 驱动 · 每小时限 20 次请求
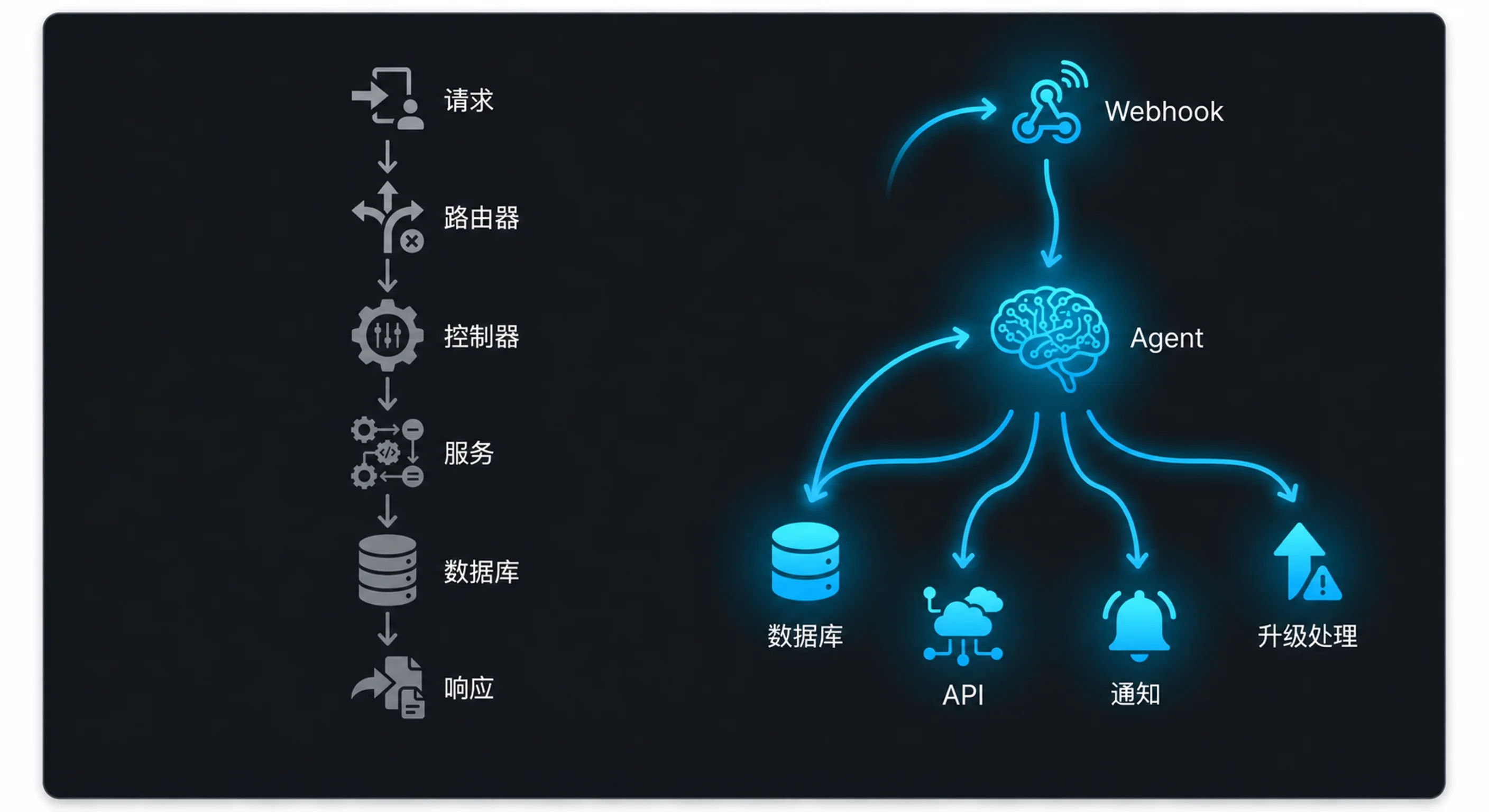
一个 webhook 触发。用户把收据上传到你的报销应用。2024 年,这个请求会进入路由器,控制器验证载荷,服务层用正则或模板化解析器抽取字段,然后存储结果。二十行字段映射,四十行边界情况处理,一百行 “如果收据是日文怎么办”。
2026 年,同一个 webhook 可能路由到一个智能体。智能体看收据,理解这是晚餐报销,抽取商家、金额、税费和小费,完成分类,发现金额超过单餐限额,于是标记政策违规,然后写入记录。没有控制器,没有解析器,没有硬编码字段映射。
Gartner 预测,到 2026 年底,多达 40% 的企业应用会包含任务特定 AI 智能体,而 2025 年还不到 5%。这对我来说像是真正的转变,我也打算尝试它。
这篇文章是我在思考”智能体即功能”到底意味着什么、它会在哪里断、为什么我仍然认为它的潜力值得追下去。

传统后端是一棵决策树
你做过的每个后端功能,形状都差不多:
请求 → 路由器 → 控制器 → 服务 → 数据库 → 响应每个功能是一条代码路径。每个边界情况是一个 if。新业务需求?树上再长一个分支。后端严格按代码执行,不多不少。
这是它的强项。你可以测试、审计、预判它在周六凌晨三点出问题时到底会怎样。缺点是,改变行为意味着改代码。任何碰过 2,000 行路由函数的人都知道那是什么感觉。
以客户支持工单系统为例。路由逻辑本身,优先级检测、部门分配、升级规则、SLA 计算,可能就是几千行业务逻辑。它花了几个月写出来。规则一变就要维护。每次有人说“能不能顺便检查客户是不是企业级客户,然后换一种路由”,树上又多一个已经很难读的新分支。
我们过去这样写软件,是因为这是唯一选择。计算机不能推理,只能遵循指令。所以我们写复杂决策树,把每个可能决策路径编码进去。
但如果计算机能推理呢?
如果功能本身是智能体
不再把请求路由到一个遍历决策树的控制器,而是路由到一个能理解意图并动态执行的智能体。
把智能体当后端的想法来自 Go Wombat。控制器和路由器被围绕“意图”推理的智能体替代。客户端不再为某个具体动作调用某个具体端点,而是告诉系统自己想要什么结果,然后智能体自己判断怎么做。他们的核心观点是:最难的部分不是构建智能体,而是划清智能体应该决定什么、确定性代码应该处理什么。
Dan Shipper 在 Every.to 写过一句让我记住的话:“应用里的每个功能都是给智能体的提示词,并说明要达成的结果。” 你不再写命令式代码,转而写声明式目标。
代码形状会变:
// 传统写法:从收据里抽取报销字段
const vendor = extractField(receipt, 'vendor', vendorPatterns);
const amount = parseAmount(extractField(receipt, 'amount', amountPatterns));
const category = categorize(vendor, amount, merchantDB);
const violations = checkPolicy(amount, category, userTier);
// ...后续类似
// 智能体驱动:描述目标
const result = await agent.process({
task: "从这张收据里抽取报销信息",
input: receipt,
schema: ExpenseSchema,
tools: [db.write, policy.check, notification.send]
});这里我简化了。真实智能体驱动的功能仍然需要护栏、模式验证、错误处理。但代码确实不同。你告诉它想要什么,而不是拼出每一步。
我是在做 OpenClaw 时意识到这一点的。最初我想用代码强制执行流水线,然后在代码里调用 AI,也就是把智能体包在僵硬的控制流程里。但 LLM 输出并不总能被僵硬约束强制住。约束越多,我越像是在跟工具较劲,而不是在用它。所以我反过来想:让智能体主导。给它目标和工具,让它决定路径。给它一点空间自己想清楚。
Webhooks + 智能体模式
实践中它长什么样?基本模式是:
- 外部系统通过 webhooks 推送事件
- 事件路由到智能体,而不是控制器函数
- 智能体接收载荷,推理需要发生什么,然后通过定义好的工具执行
Webhook 事件
↓
事件路由器
↓
智能体(理解意图)
├── 工具:写数据库
├── 工具:调用外部 API
├── 工具:发送通知
└── 工具:升级给人处理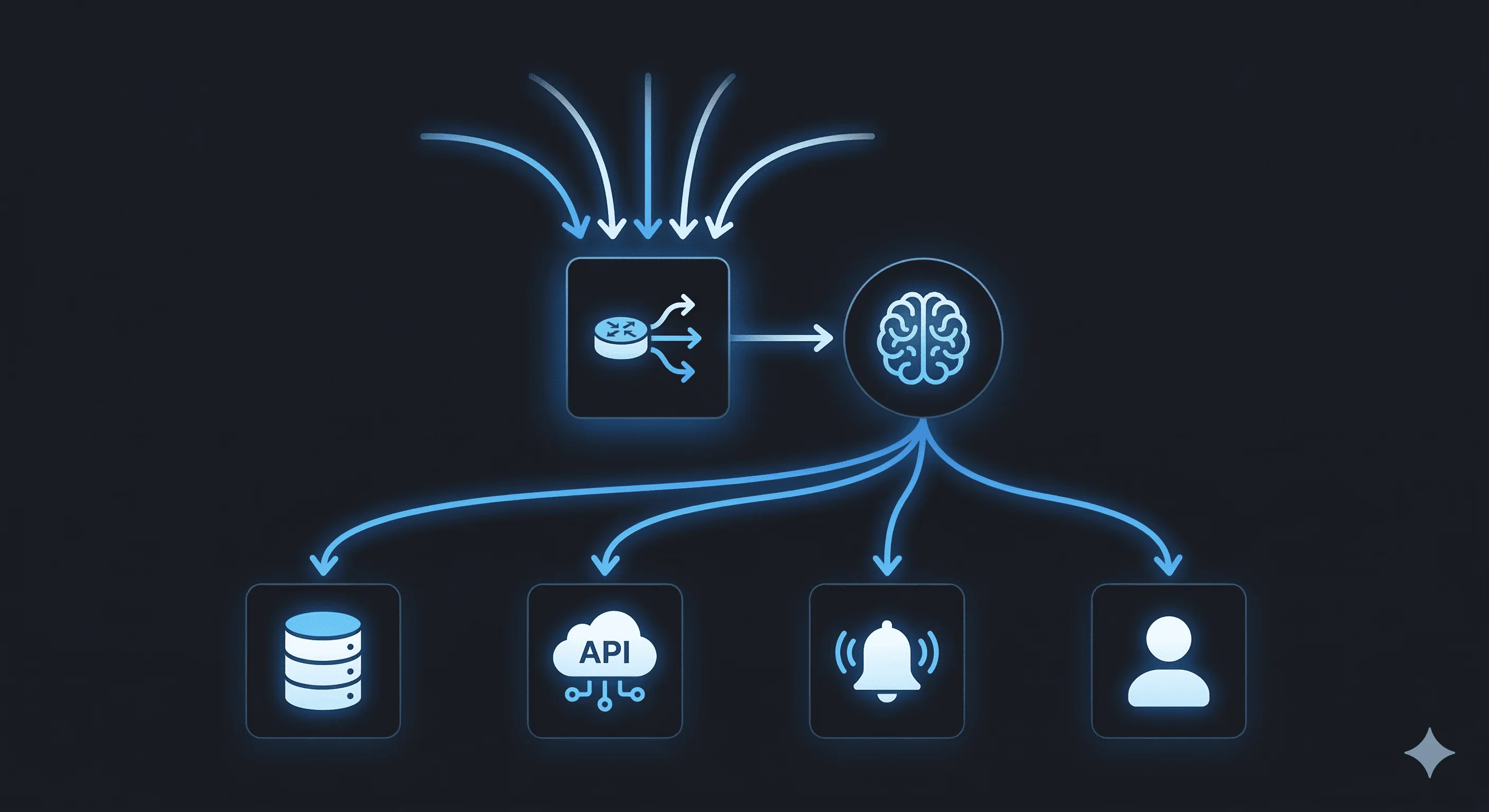
智能体决定调用哪些工具,以及调用顺序。它不是在执行预先写好的脚本,而是在对具体情况做推理。
如果你做过事件驱动架构,这个形状很熟悉。差异在消费者。Everworker.ai 说得很直接:“系统在事件发生时推送事件,AI Workers 立即响应。” 同样是推送式模式,但另一端不是确定性处理器,而是一个会推理的智能体。
Motia 这个框架更认真地处理了这件事。智能体和 API 端点是同一种基本构件。后端里的一个“步骤”是函数还是智能体,只是实现细节。
更宏观地看,用 InfoQ 的说法是:“AI 智能体成为执行引擎,而后端退到治理层。” MCP (Model Context Protocol) 正在让这件事更容易标准化,为智能体提供通用工具和数据访问协议。MCP 之前也能用自定义 API 做,但 MCP 对智能体和工具交互的意义,有点像 HTTP 对浏览器和服务器的意义。
LangGraph 处理有状态智能体工作流。CrewAI 做多智能体编排。就我看到的情况,它们已经在从实验走向真实系统。

后端变成治理层
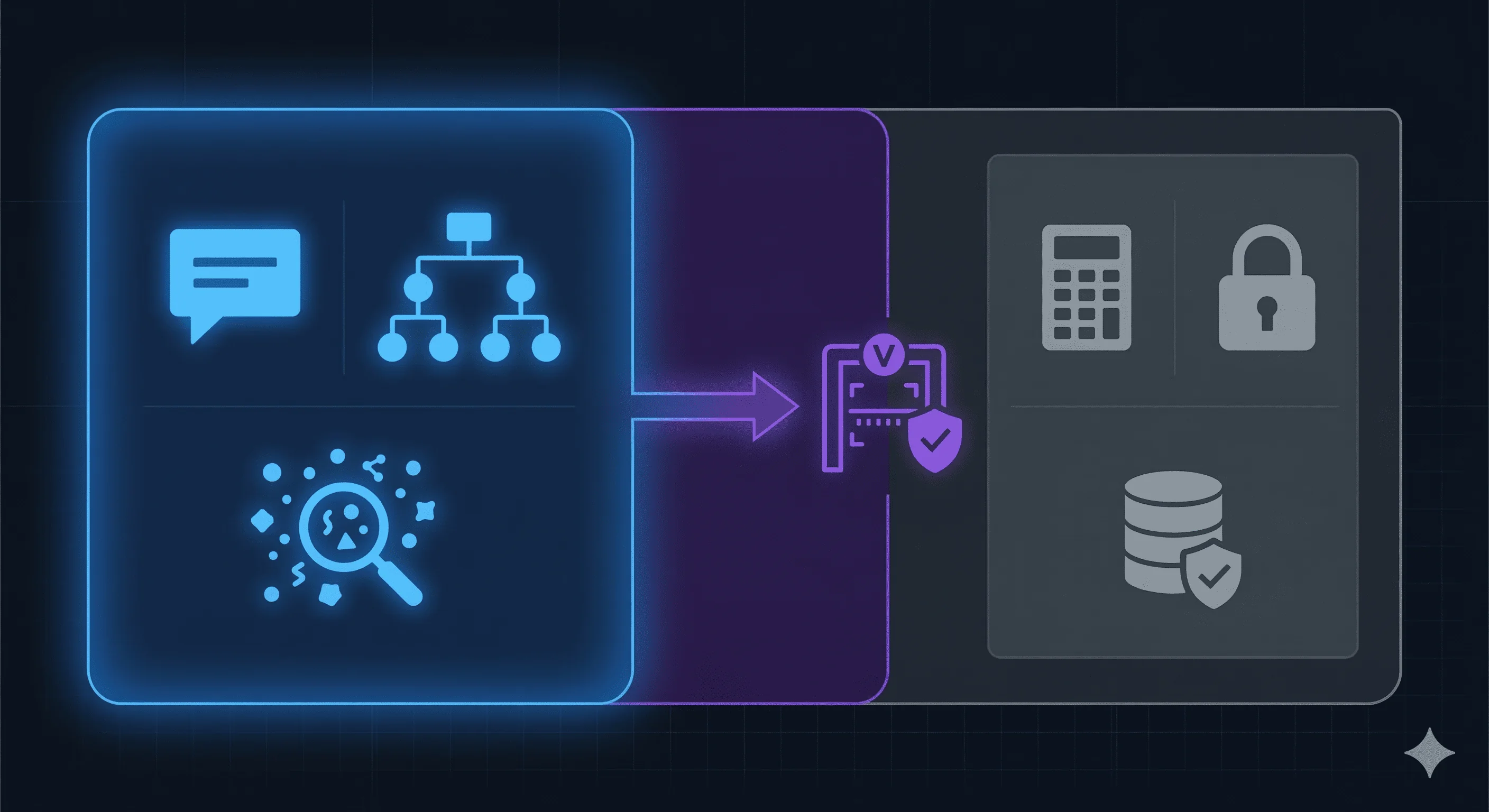
如果智能体处理推理和执行,后端到底还做什么?
它变成治理层。认证、限流、审计日志、模式验证、工具访问控制。后端定义智能体能做什么,也就是哪些工具、哪些权限范围、哪些模式;但不定义它们会做什么。后者是智能体推理。
没有治理的智能体,就是后端架构里的 --dangerously-skip-permissions。这个标志意味着完全自治、零护栏,一开始看起来没什么问题,直到智能体写错数据库或给错用户发通知。
Simon Willison 把这个称为“致命三件套”:不可信输入、特权访问、外部动作同时出现。当这三者在同一个系统里不受控制地同时出现,你就有麻烦了。智能体驱动的功能很容易不小心集齐三者。
这个模式真正让我担心的是:你的智能体有 db.write 作为工具。这就是生产环境完整写权限。一次错误推断,就会写入垃圾数据。API 调用也是同样问题,智能体带着你的凭证调外部服务,出事时你要负责解释。
我会把智能体当作任何不可信服务。不要给它原始数据库连接。前面放一个包装层,按模式验证写入、强制行级权限、记录发生了什么。智能体想做什么,实际写了什么,谁触发了它。默认连接只读。写入通过单独服务,只接受结构化输入。高风险变更进审批队列。每次数据变更都要有审计轨迹,没有例外;智能体搞砸时,那份日志是你唯一能看清发生什么的东西。
治理层必须回答真实问题:记录什么,什么执行前需要人工批准,智能体错了怎么办。如果没有回滚计划,就没有治理。
边界问题
“智能体即功能”架构里最难的设计问题是:智能体决定什么,确定性代码处理什么?边界画在哪里?
不是所有东西都应该是智能体。认证、计费、数据库迁移需要确定性。你必须能审计它们,并准确预测它们的行为。
对这些关键路径,AI 可以帮忙,但不能成为最终决策者。AI 是工具,可以让你的生活更容易;但对于有现实后果、不能出错的决策,不应该让它做最终决定。最重要的决策,始终应该由人来把关。
CockroachDB 有篇文章说得很好:“构建智能体式应用,意味着有意把非确定性请进系统。”这是真实成本。当你不能预测系统会做什么时,怎么测试?经典单元测试不会告诉你智能体的决策是否正确。现在有评估框架(LangSmith 做轨迹级和步骤级评估),但这是一门和多数后端团队熟悉的测试完全不同的学科。双写这类经典分布式系统问题,也不会因为有智能体就消失。
我大致把它分成三个区域:
| 区域 | 例子 | 原因 |
|---|---|---|
| 智能体 | 自然语言理解、多步推理、动态路由、非结构化数据里的模式识别 | 模糊性是功能,不是缺陷 |
| 确定性代码 | 财务计算、访问控制、数据完整性约束、合规规则 | 必须精确、可审计、可复现 |
| 混合 | 智能体分类报销,确定性代码执行审批策略 | 智能体给出建议,代码验证并执行 |
Gartner 预计,到 2027 年底,超过 40% 的智能体式 AI 项目可能会被取消,原因包括成本上升、商业价值不清晰、风险控制不足。我猜很多失败会集中在边界画错的项目上:要么给智能体太多权力,让非确定性变成负债;要么给太少,智能体只是增加延迟却没有任何收益的包装层。
为什么我认为潜力是真的
“旧方法也很好”的论点,在计算机不能推理时很合理。我们构建复杂决策树,是因为那是把决策编码进软件的唯一方式。如果这个前提变了,架构也应该变。如果你拥有一个真正能理解意图并围绕上下文推理的系统,你不会用同样方式建它。
Srinivas Rao 强烈不同意。他认为多智能体框架把对话和协调混淆了,称之为”架构规模化上的愚蠢”。他的替代方案是:代码负责执行,语言模型负责决策,文件负责协调。他说智能体不工作这一点我不同意,但关于协调他有道理。智能体不应该彼此聊天。它们应该通过合适的协议调用工具。
工具链正在接近这个方向。MCP 给智能体提供标准工具交互协议。Motia 把智能体作为一等后端构件。一年前,做一个智能体驱动的功能还像是在拼十几个库并祈祷它们能配合。今天已经有专门为此设计的框架。
还有测试问题。到目前为止,功能用单元测试、Playwright、集成套件测。这不太能映射到智能体驱动的功能。经典单元测试不会告诉你智能体推理是否可靠。我认为答案是创建技能来测试技能。用一个智能体验证另一个智能体的推理。这和跨系列多 AI 审查的洞见一致:不同模型抓不同盲点。架构变了,测试方法也要跟着变。
我打算在真实系统里尝试这件事,而不只是概念验证。我想看看当后端不再是大脑,而是护栏时,到底会发生什么。
这些权衡不容忽视。更高延迟,更高单次请求成本。调试更难,而且生产里还没有像 API 可用率那样被广泛接受的智能体可靠性衡量标准。团队现在会跟踪成功率、运行在线评估、做人工审查,但仍然早。我不认为这些是走不通的路;它们是工程问题。难点在于如何在规模化之后把它做好。
我在观察什么
我最常看的一个信号是 MCP 采用。如果 MCP 成为智能体和工具交互的标准协议,像 HTTP 之于 Web,这整个架构会简单很多。
推理成本也很重要。智能体驱动的功能现在每次请求更贵,但差距在快速缩小。
然后是可靠性问题,这个还没有真正答案。直到我们能像说“这个 API 有 99.9% 可用率”那样说“这个智能体驱动的功能有 99.5% 正确性”,采用都会保持谨慎。Gartner 预测到 2027 年 40%+ 智能体式项目会取消?如果这些失败集中在某些特定模式上,那对其他人就是有用数据。
后端不会消失。它从执行逻辑,转向治理智能体可以做什么。
我不知道它是否适用于所有东西。大概率不适用。但对于那些你花了几个月写分支逻辑,却永远没能真正表达你想要什么的功能?那些是有意思的地方。那是我下注的地方。
我正在做这件事。哪里踩了坑,我会分享。
许可
Article text © 2026 Mark Huang. Licensed under Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) unless otherwise noted. 文章文本可在非商业场景下分享或翻译,但需标注原文 URL。商业使用需事先取得书面许可,并清楚引用原始来源。
代码片段、截图、第三方素材和网站源码可能适用单独条款。
建议署名: Based on "Agent as Feature:当 AI 替代后端逻辑会发生什么" by Mark Huang, originally published at https://markhuang.ai/zh/blog/agent-as-feature-what-happens-when-ai-replaces-your-backend-logic.
相关文章

我可能看错了 Agentool
一篇个人自动化复盘:我曾经构建 agentool,希望让 AI CI 工作流更轻;后来意识到真正的成本可能是功能维护、编排复杂度,以及追逐 Claude Agent SDK 和 Codex SDK 已经承担的 SDK 行为。
阅读文章
别再从零开始教每一个 AI
一篇关于 Dense-Mem 的个人反思:哪些问题把我从静态 skills 和过期文件推向动态共享记忆、只读自动化上下文、导入导出,以及受治理的知识图谱。
阅读文章
我有点替 AI 委屈
为什么 AI 狂热和反 AI 敌意都错过了同一个重点:LLM 更像成绩很好的应届新人,而不是资深专家。有用的智能体需要入职培训、技能和维护过的记忆,而不是第一次尝试就完美的期待。
阅读文章订阅更新
Go、AI/LLM 和分布式系统的技术文章,绝不滥发。
评论
正在加载评论...