博客
关于 AI 系统和生产软件建设的思考、现场笔记与实践文章。
- 文章
- 31
- 阅读时间
- 4 小时 14 分钟
- 分类
- 2
我可能看错了 Agentool
一篇个人自动化复盘:我曾经构建 agentool,希望让 AI CI 工作流更轻;后来意识到真正的成本可能是功能维护、编排复杂度,以及追逐 Claude Agent SDK 和 Codex SDK 已经承担的 SDK 行为。
阅读文章

别再从零开始教每一个 AI
一篇关于 Dense-Mem 的个人反思:哪些问题把我从静态 skills 和过期文件推向动态共享记忆、只读自动化上下文、导入导出,以及受治理的知识图谱。
阅读文章
我有点替 AI 委屈
为什么 AI 狂热和反 AI 敌意都错过了同一个重点:LLM 更像成绩很好的应届新人,而不是资深专家。有用的智能体需要入职培训、技能和维护过的记忆,而不是第一次尝试就完美的期待。
阅读文章
Skills + Dense-Mem:让 AI 工作流从经验中学习
一个关于组合 AI skills 与 Dense-Mem 的假设:把工作流、安全规则和验收标准放进 skills,让记忆保存期望、示例、修正、失败和可迁移的 skill-pack 知识。
阅读文章最新文章

5 分钟试用 Dense-Mem 托管演示
一篇快速教程:使用托管的 Dense-Mem 测试实例,把 Claude Code 和 Codex 接到同一份临时记忆,并观察共享上下文如何让 AI 更聪明地工作。

Dense-Mem 快速开始:让 Claude Code 和 Codex 使用同一份记忆
一篇面向初学者的教程:启动本地 Dense-Mem 服务器,创建第一把 memory key,并把 Claude Code 和 Codex 接到同一个共享 AI 记忆大脑。

用 Traefik 在 Vultr 上安全部署 Dense-Mem
一篇非技术读者也能跟上的 walkthrough:在 Vultr 云服务器上启动 Dense-Mem,配置 Traefik、HTTPS、私有控制台访问,以及给个人、家庭或工作 AI 工具使用的共享记忆。
System Prompt 与 User Prompt:GenAI 功能下面的那一层
一篇面向初学者的 system_prompt 与 user_prompt 解释,用 ChatGPT、Claude Projects、Claude Cowork 和 Claude Code 作为例子。

RAG 之外的 AI 记忆:向量、图谱和 Dense-Mem
RAG 不是魔法记忆。本文用实践视角解释 chunk、embedding、向量搜索、图谱支撑的记忆,以及为什么持久 AI 记忆需要来源证据、冲突处理和检索策略。

AI 是坏的吗?
AI 可以让你更快、更懒、更有能力,也更依赖外部系统。真正的问题不是 AI 好不好,而是你选择外包哪部分知识,以及这笔交换是否值得。

从软件开发者到 AI 架构师:这一年改变了什么
一段从 Claude Code skills,到 TypeScript 状态机、MCP 工具,再到 SDK 式 AI 工作流的个人路径。技能有帮助,工具有帮助,但提示词不是约束,LLM 也不该拥有控制平面。

“我的公司不需要 AI。”再想想。
AI 采用不只是选择工具。即使自认为不需要 AI 的公司,也需要理解 AI 应该放在哪里、哪些东西必须保持确定性,以及谁来负责定制、安全和长期控制。

三个臭皮匠,顶个诸葛亮:让便宜模型协同工作
一堂来自中文俗语“三个臭皮匠,顶个诸葛亮”的个人 AI 架构课:为什么便宜模型会被巨大提示词压垮,以及聚焦的专家会话、编排、综合和温度控制如何让它们变得有用。

确定性的交易:为什么我用 15 分钟的 N8N 归档了自己的智能体框架
我花两个月构建 OpenHive,也就是自己的 OpenClaw,想为一人公司探索 Agent as Feature。它做到 v4,90% 可用,却仍会输出我没要求的日志。我用 N8N 花 15 分钟重建了同一个监控器。这里是我对 LLM 适合位置的复盘。

1+1 假说:能否把编程问题拆到任何 LLM 都能做?
每个 LLM 都会算 100×100,每个编程 LLM 都能重命名变量。但可靠性从哪里开始断裂?工程化 harness 能不能把边界往前推?本文讨论剩余解空间熵、测试先行契约、分层防御架构,以及为什么盲目共识会失败,而验证式搜索有效。

不,中文对 LLM 并不比英文更省 token
一位中文母语者测试“中文字符更省 token”这个流行说法。跨六种 tokenizer,包括 Qwen、GLM、DeepSeek 等中文优先模型,英文每次都使用更少 token。本文讨论数据、BPE 机制,以及为什么字符数和 token 数不是一回事。

没有意图的自动化,只是更快的混乱
三套失败的流水线架构,一次关于反压的教训,以及最终让多 AI 氛围编程跑起来的 UAT 门。本文复盘什么坏了、什么留下来,以及为什么知道自己想要什么比工具本身更重要。

你不觉得你的 AI 太乐观了吗?
RLHF 可能奖励迎合而不是准确,把 AI 变成裹着糖衣的子弹:看似认可,实则隐藏失败模式。本文讨论持续的对抗性规则如何把默认行为从奉承改成诚实质疑。

Agent as Feature:当 AI 替代后端逻辑会发生什么
Gartner 预测到 2026 年,40% 的企业应用会嵌入 AI 智能体。Agent as Feature 模式用推理型智能体替代确定性控制器。本文探讨这对后端架构意味着什么,以及为什么这个潜力是真实的。
为什么一个 AI 永远不够
医学、法律、科学和金融等高风险行业都要求独立复核,AI 却常常跳过这一步。37% 的企业已经使用 5 个以上模型,但多数仍是临时拼接。跨模型家族多 AI 系列第一章。
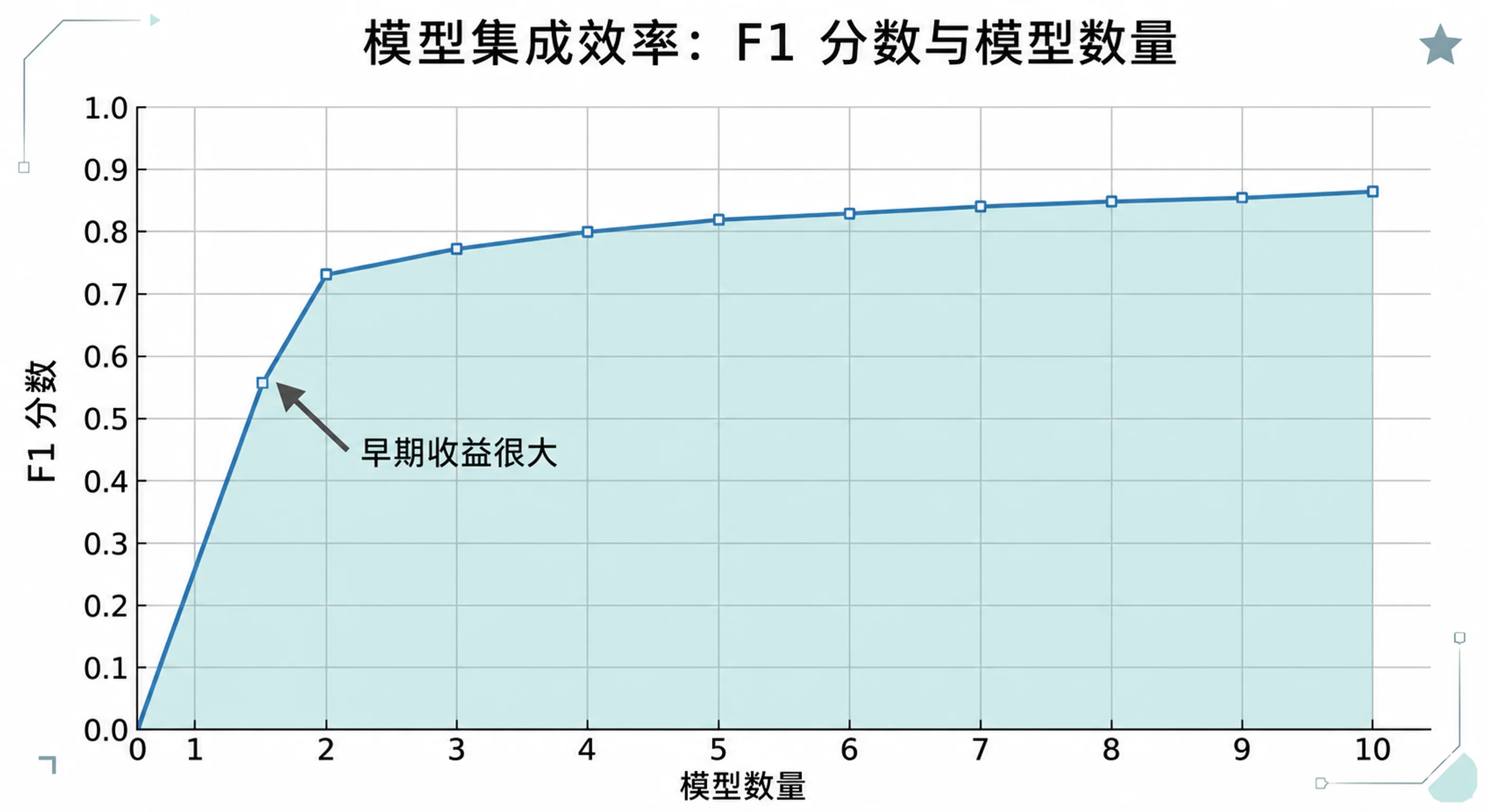
集成智能背后的科学
群体智慧遇上 AI:多样化 LLM 集成超过 67% 的单一模型,F1 分数从 0.55 提升到 0.80 以上,而 56.9% 的最佳方案来自最弱模型。跨模型家族多 AI 系列第二章。
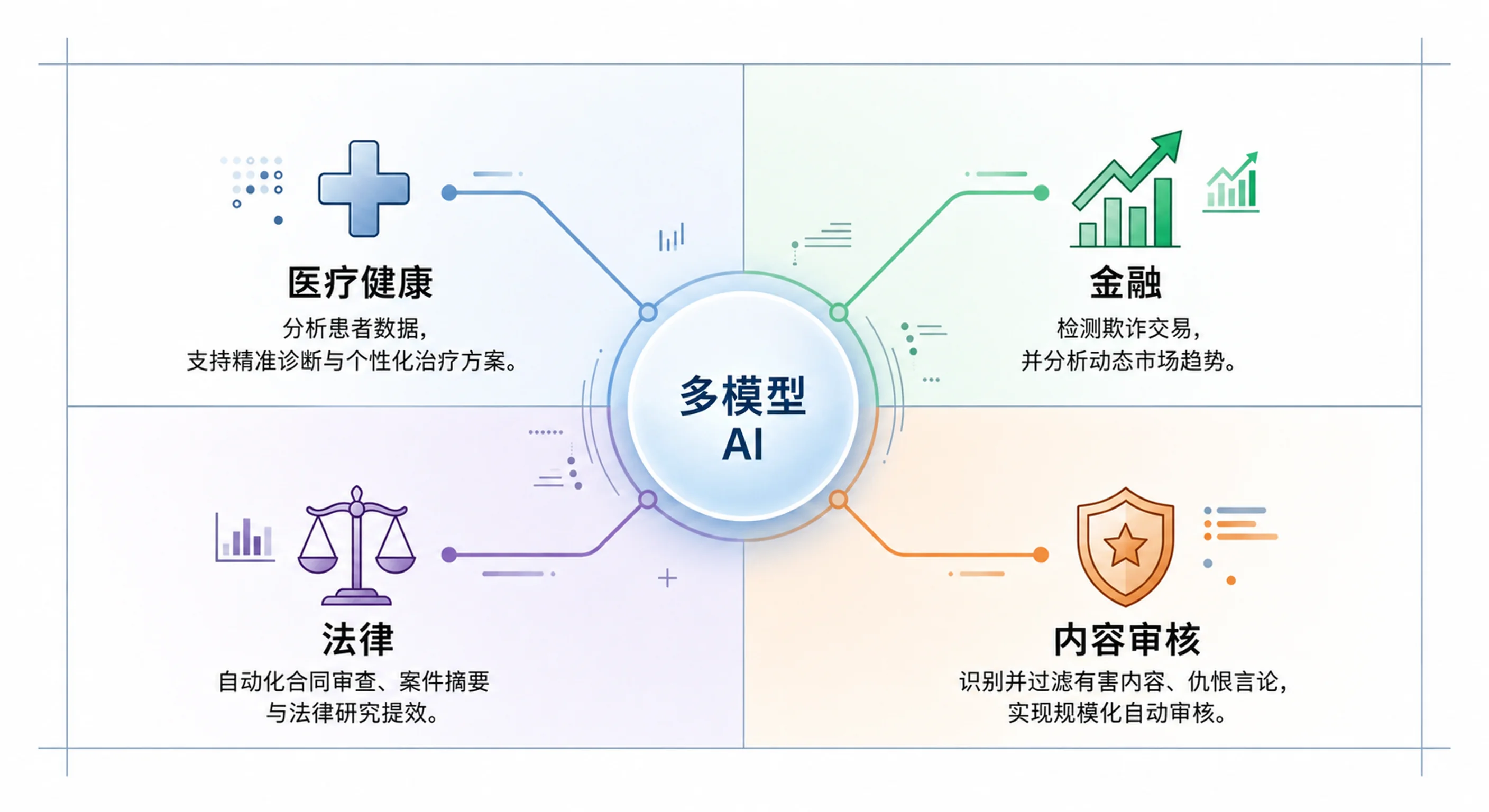
行业证据:医疗、金融、法律以及更多场景
多模型 AI 已经进入医疗诊断、金融风险管理、法律分析和内容审核的主流实践。本文整理四个行业的证据,以及它们对跨模型家族 AI 采用的意义。跨模型家族多 AI 系列第三章。
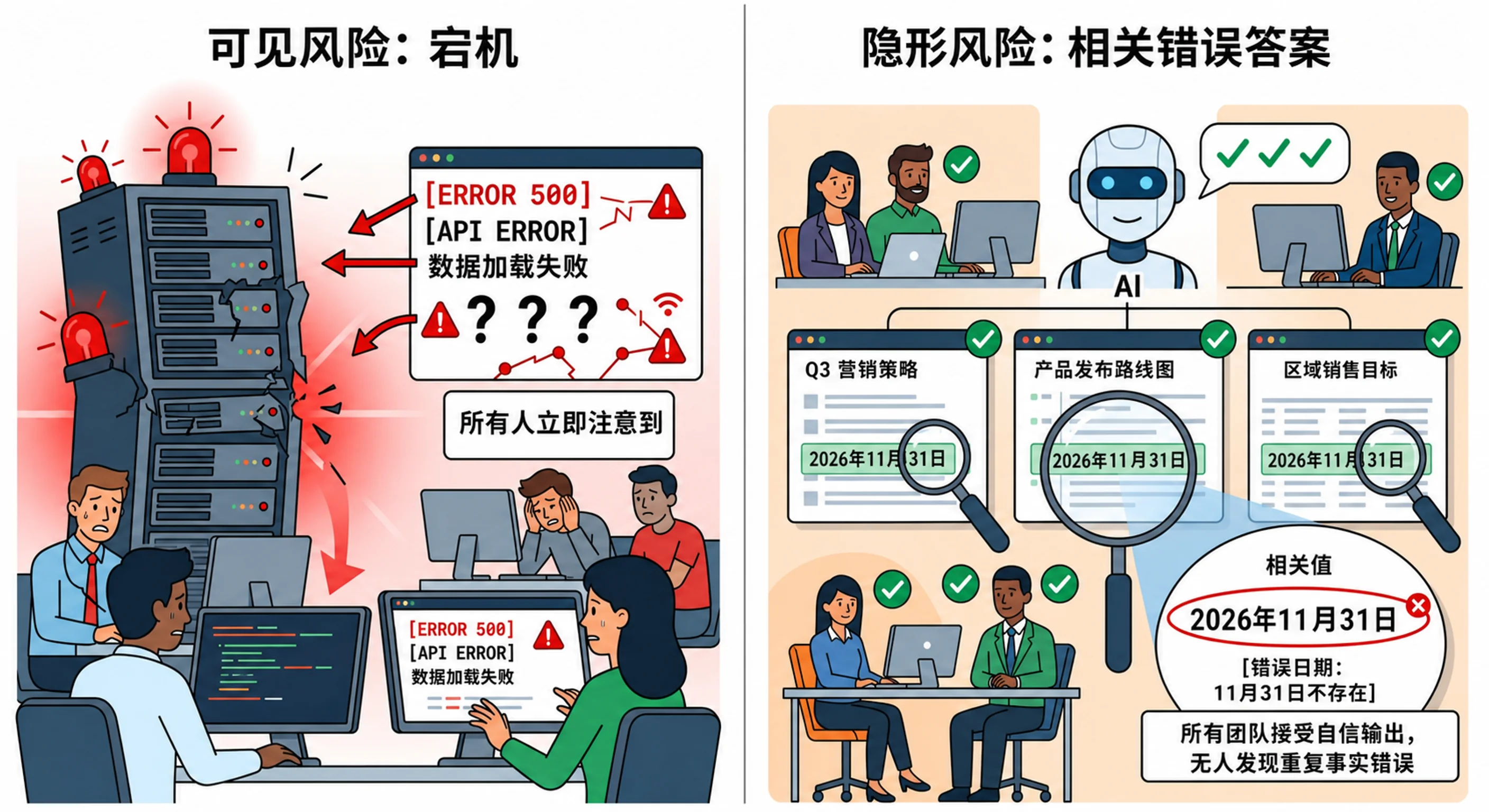
模型单一化风险:当所有 AI 都同意同一个错误答案
依赖单一 AI 的危险不只是宕机,而是相关性错误:答案错了,却没有任何系统反驳。当每个团队使用同一个模型家族,同样的盲点会安静地扩散。跨模型家族多 AI 系列第四章。
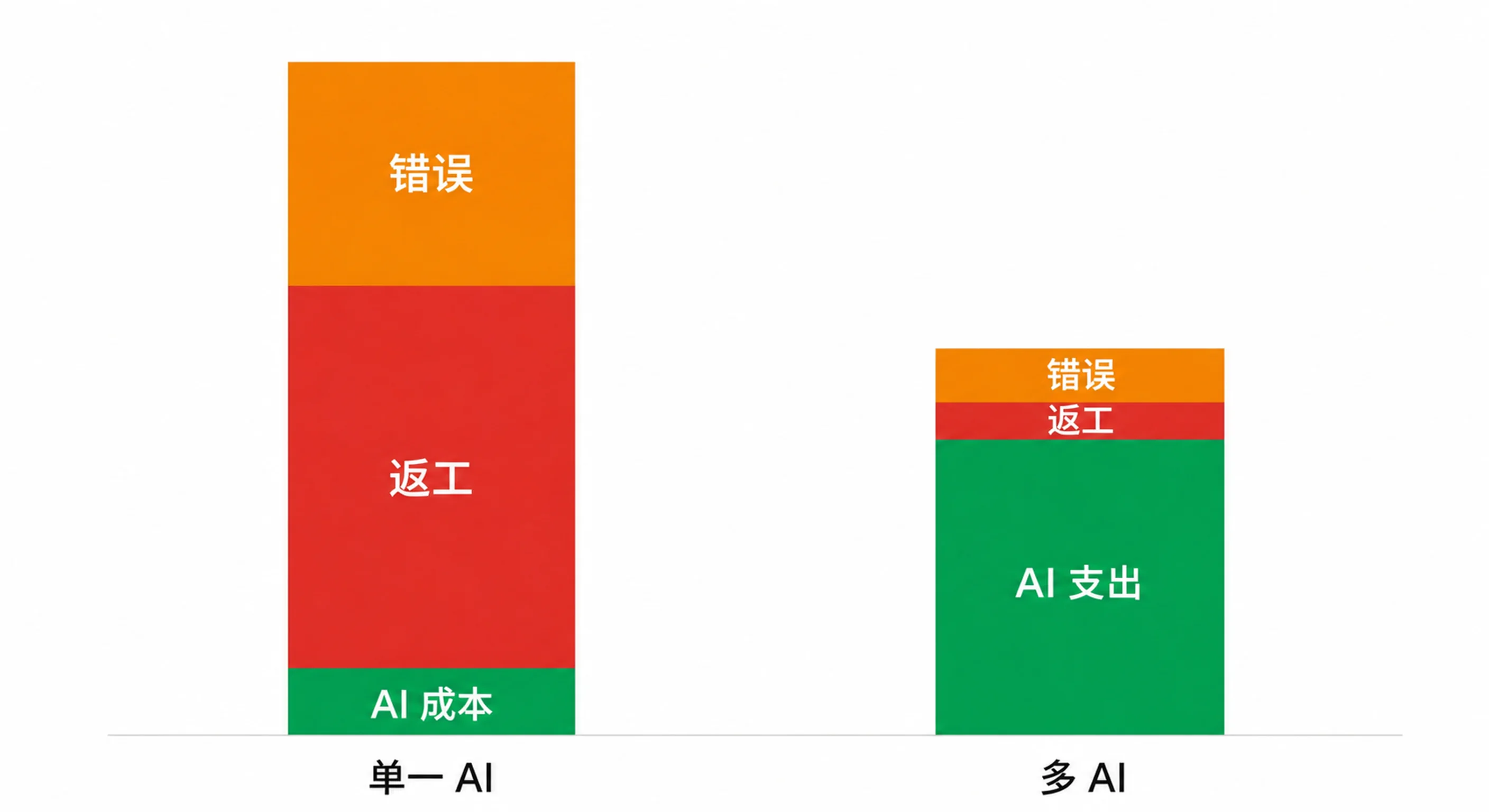
成本问题:什么时候多 AI 能收回成本
多 AI 的 token 成本可能高出 3 到 4 倍,但组织会把 40% 的 AI 生产力收益浪费在返工上。本文讨论执行顺序、按任务缩放,以及成熟与不成熟 AI 实践之间 21 倍 ROI 差距。跨模型家族多 AI 系列第五章。