RAG 之外的 AI 记忆:向量、图谱和 Dense-Mem
RAG 不是魔法记忆。本文用实践视角解释 chunk、embedding、向量搜索、图谱支撑的记忆,以及为什么持久 AI 记忆需要来源证据、冲突处理和检索策略。
AI 驱动 · 每小时限 20 次请求

答案快照
到 2026 年,“AI 记忆”已经不是一个单一功能。大多数时候,人们说的其实是下面五层之一。每一层有用,也各有自己的失败方式。
| 层次 | 负责什么 | 常见失败 |
|---|---|---|
| 提示词记忆 | 把指令加载进上下文 | 上下文缺失或表达模糊时,规则会被漏掉 |
| RAG | 找到外部文本,再注入上下文 | 可能检索到过时或不完整的证据 |
| 向量记忆 | 检索语义相近的内容 | 相似文本仍然可能给出错误答案 |
| 图谱记忆 | 保存事实、关系、历史和冲突 | 没有验证关卡时,坏事实会长期留在系统里 |
| 持久记忆 | 组合检索、状态、来源和更新策略 | 缺掉任何一层,信任都会塌 |
我现在用的实用规则是:检索负责找文本;记忆负责判断什么是当前的、可信的、并且和这次任务相关。这也是为什么提示词放在哪里仍然重要;更简单的心智模型可以看 系统提示词与用户提示词。
这个区分很重要。如果把检索当成记忆,系统可以找到旧文本,却不知道哪个事实才是当前事实。如果把 Embedding 当成“理解”,你可以做出一个很快的搜索系统,但它仍然会返回错误证据。如果加了图谱却没有清晰关卡,你会把嘈杂对话变成一套看似自信、其实被污染的记忆。
所以我们把这些部分拆开看。
Claude Code 记忆是上下文,不是数据库
Claude Code 内建记忆很有用,但它不是向量数据库或图谱记忆系统。
按照当前 Claude Code 记忆文档,每个会话都从新上下文窗口开始。跨会话携带知识有两个机制:你写的 CLAUDE.md 文件,以及 Claude 从纠正和偏好中写下的自动记忆笔记。两者都会在对话开始时加载。Claude 把它们当上下文,而不是强制执行的配置。
最后一句是关键。
CLAUDE.md 可以写:
完成代码修改前始终运行 npm test。
优先做小而聚焦的修改。
API 处理器位于 src/api/handlers/。这能帮助模型行为更一致,因为指令在上下文里可见。但它不会创建一个可搜索的语义记忆系统。它不会给每一次历史对话做 Embedding,不会维护冲突解决,也不会自动知道某个偏好已经被新偏好取代,除非新事实同样出现在可见上下文里,而且模型真的遵循它。
自动记忆也是同理。它是持久上下文,不是知识图谱。文档当前描述自动记忆会加载到每个会话,限制在前 200 行或 25KB。这足够保存实用的指南,但不够支撑长期、高容量、带证据追踪的记忆。
所以我把 Claude Code 记忆看成 “启动上下文”。它很适合指令、约定、辛苦得来的项目笔记。它不是 AI 记忆的完整答案。
RAG 默认不是关键词上下文
很多人脑子里的 RAG 是这样:“搜一个关键词,抓它前后 100 个字符,粘进提示词。”
这种东西可以存在,但它不是 RAG 的定义。
RAG 是检索增强生成。系统先检索外部信息,再把这些信息作为额外上下文交给模型生成答案。检索部分可以是关键词搜索、向量搜索、混合搜索、图谱遍历、SQL 过滤、重排,也可以是这些方式的组合。
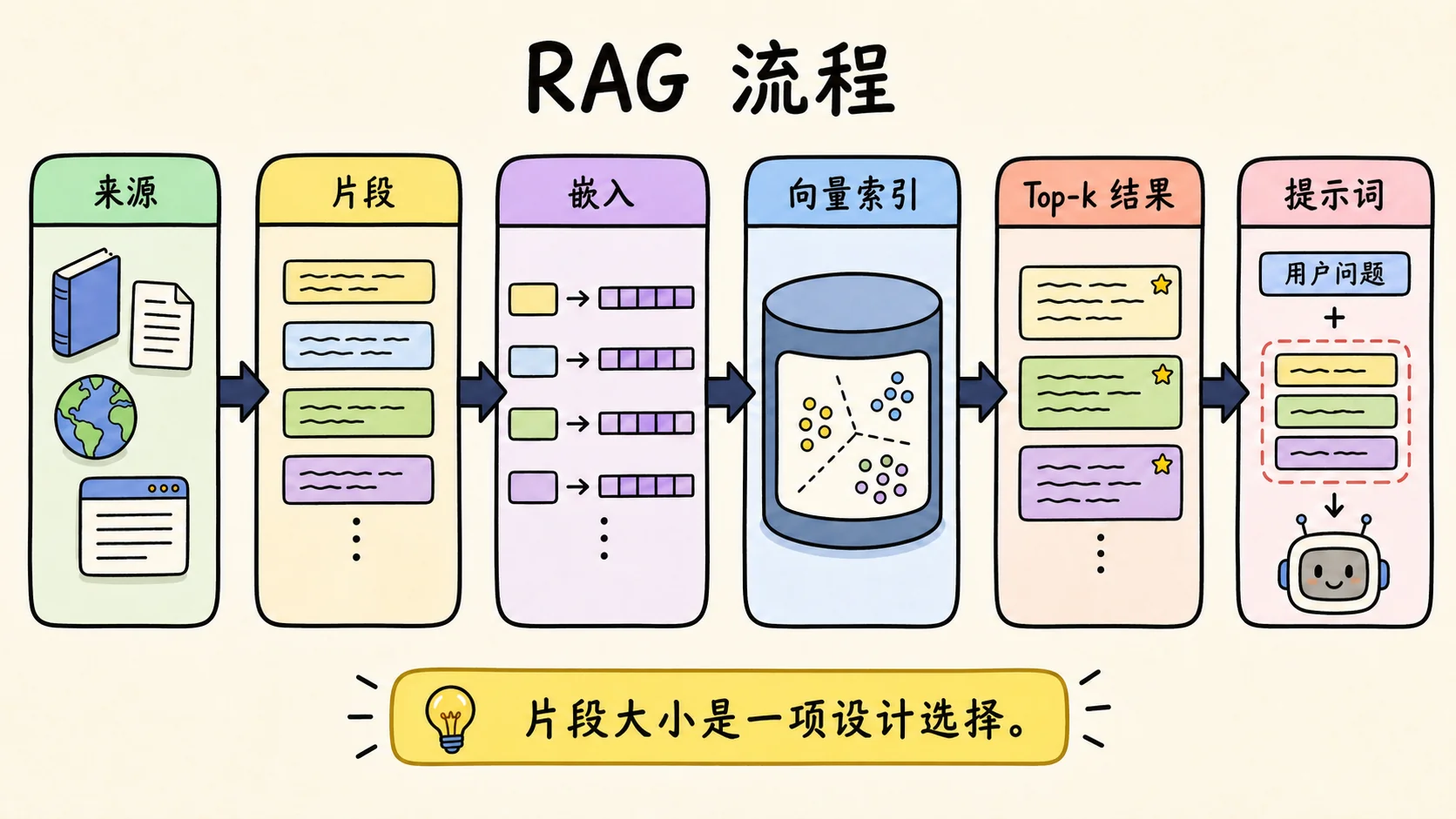
典型的向量 RAG 搭建大概是这样:
- 收集源文档。
- 把文档切成片段。
- 把每个片段转成向量。
- 把向量加元数据存进索引。
- 查询时,把用户问题也转成向量。
- 检索最接近的片段。
- 把这些片段注入提示词。
“片段”本来就不是固定大小的。它可以是 300 个 token、800 个 token、一个段落、一个 Markdown 小节、一个代码符号,或者一个语义段。有些系统会加重叠区。有些系统会在找到第一个结果后,再拉取相邻片段。有些系统会在 LLM 看到候选内容前,用重排模型重新排序。
所以正确说法不是 “RAG 会抽取关键词附近 100 个字符”。
更准确的说法是:RAG 检索的是你配置好的上下文单位;质量高度依赖你怎么切片、做 Embedding、建索引、过滤、重排,以及最后怎么组装上下文。
限制不是 RAG,而是无状态检索
当答案确实存在于语料里时,RAG 很强。
如果我问 “这个服务用什么端口?”,RAG 可以找到 README、配置文件或部署笔记。如果我问 “用户上个月说过 Neo4j 什么?”,RAG 可以检索那段对话片段。
但记忆面对更难的问题:
3 月 1 日:“我偏好用 Postgres 做项目记忆。”
4 月 10 日:“其实我想给这个记忆项目用 Neo4j。”
今天:“我的记忆项目应该用什么数据库?”纯检索系统可能同时找到 3 月和 4 月那两段话。它可以把两段都交给模型,然后指望模型自己推理出正确答案。有时没问题。有时模型会选中已经过时的事实,把两者混在一起,或者过度自信地回答。
这不是向量搜索失败,而是状态管理失败。
持久记忆需要知道的不只是“什么文本和问题相似”。它还要知道:
- 说过什么?
- 谁说的?
- 什么时候说的?
- 这是证据、声明,还是已经接受的事实?
- 它是否与现有事实冲突?
- 旧事实是否已经被取代?
- 它属于哪个配置档或项目?
- 这次任务是否应该召回它?
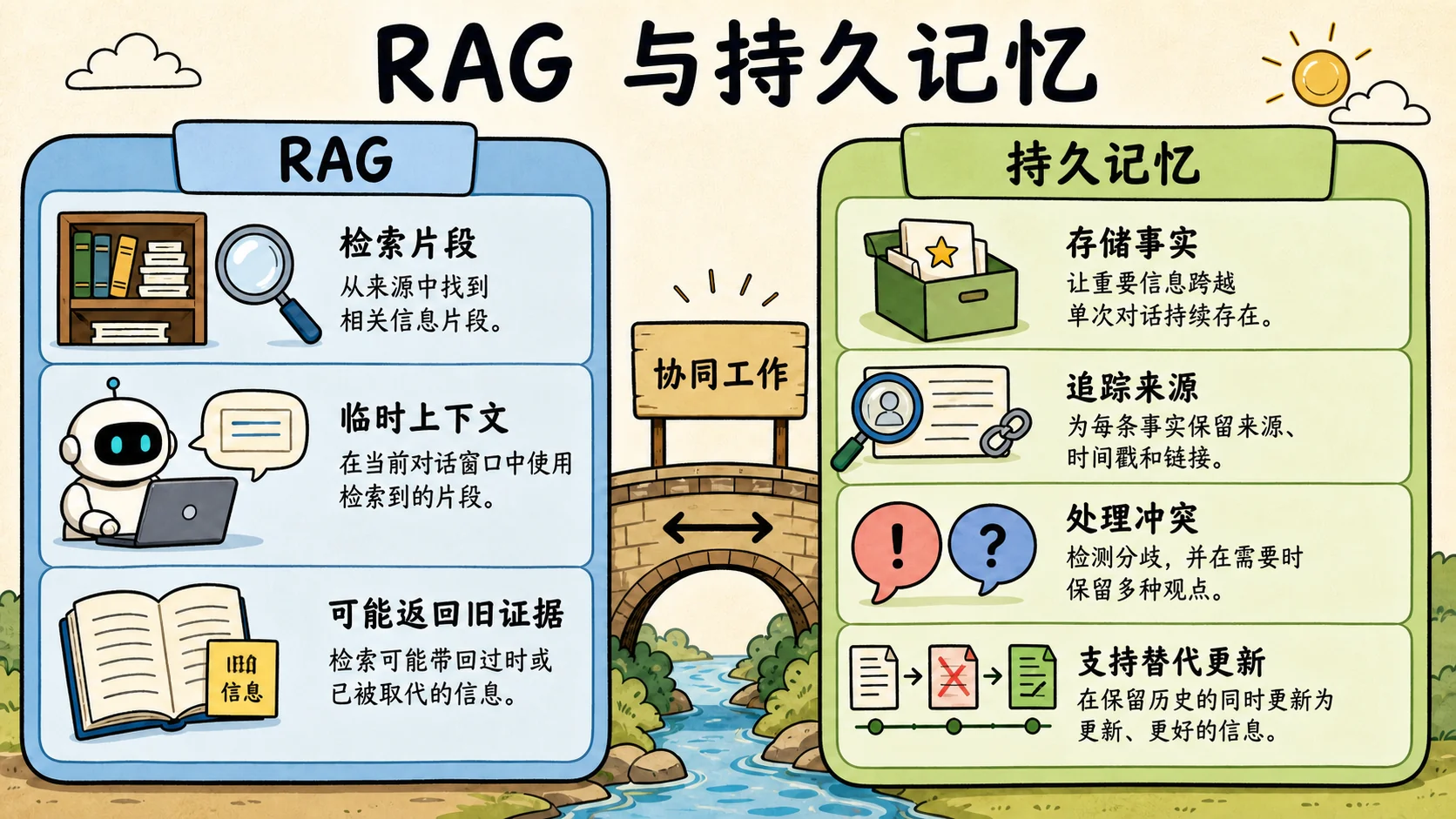
这就是图谱支撑的记忆开始变得重要的地方。不是因为图谱数据库有魔法,而是因为记忆本来就是有关系、有历史的。
Embedding 实际做什么
Embedding 模型把文本变成数字。
更精确地说:一段输入文本会变成一个向量。一批文本会变成一个矩阵,因为多个向量被堆在一起。
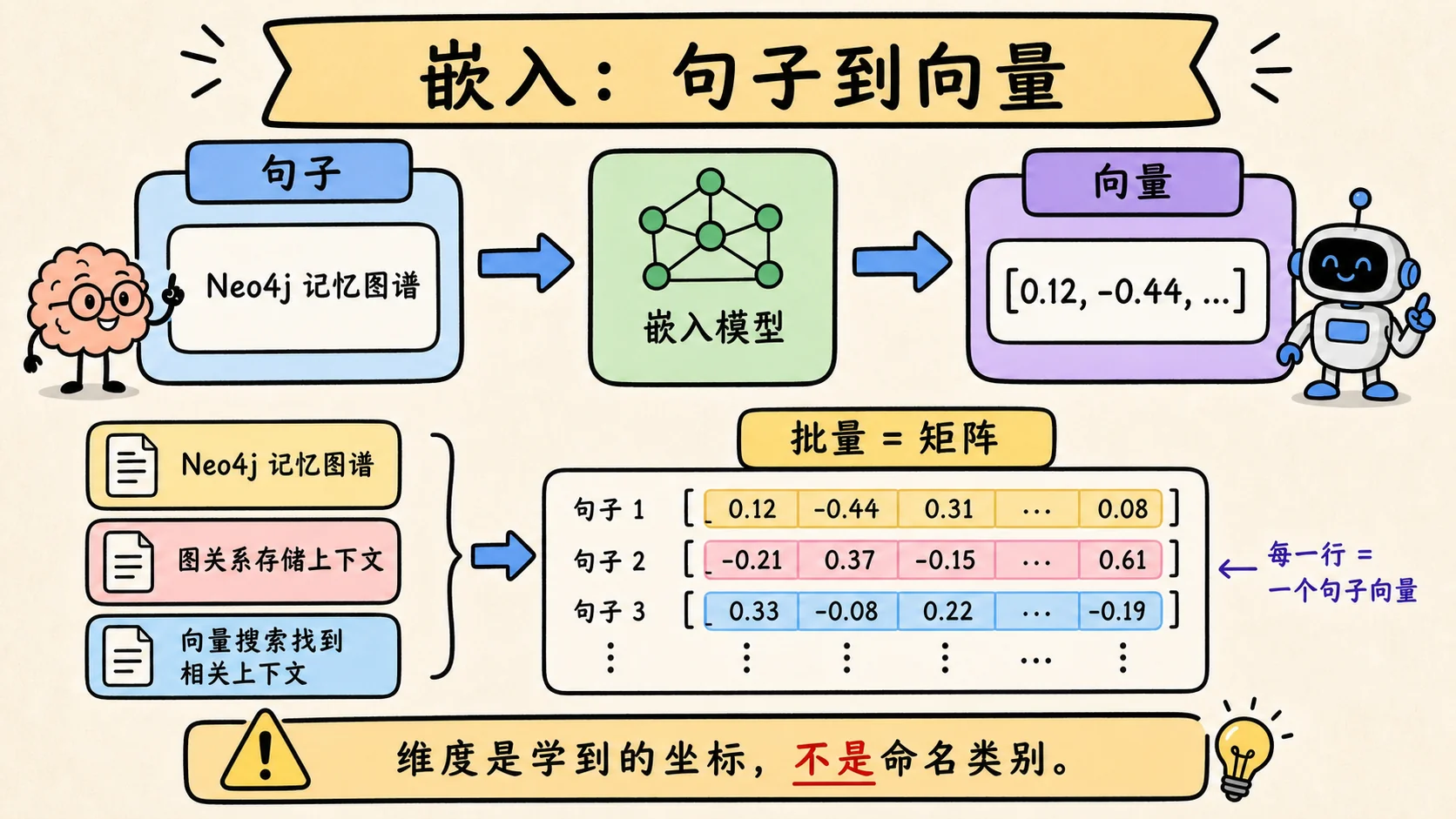
比如:
"用户偏好用 Neo4j 做记忆图谱。"
-> [0.12, -0.44, 0.31, ... , 0.08]这些数字不是随机 ID。它们是模型学到的坐标。Embedding 模型经过训练后,会让意义相关的文本在向量空间里更接近。
但这些维度不是人类命名好的分类。
一个 768 维向量不是:
维度 1 = 数据库属性
维度 2 = 项目属性
维度 3 = 偏好属性
...
维度 768 = 记忆属性这个解释很诱人,但过于表面了。维度是模型学到的潜在坐标。人类有时能解释 Embedding 空间里的某些方向,但这些坐标不是一套干净的分类法。
更多维度可以给模型更大的容量来保存信号,但”更多维度”不自动等于”更准确”。弱模型生成的 3,072 维 Embedding,可能不如一个更适配你领域的 768 维 Embedding。检索质量取决于 Embedding 模型、训练数据、语言和领域适配、归一化方式、片段质量、元数据过滤,以及评估集。
Embedding 模型很重要,因为它决定“接近”到底是什么意思。
向量数据库搜索是什么意思
搜索向量数据库时,你问的不是:
哪篇文档包含这个精确词?你问的是:
哪些已存向量最接近查询向量?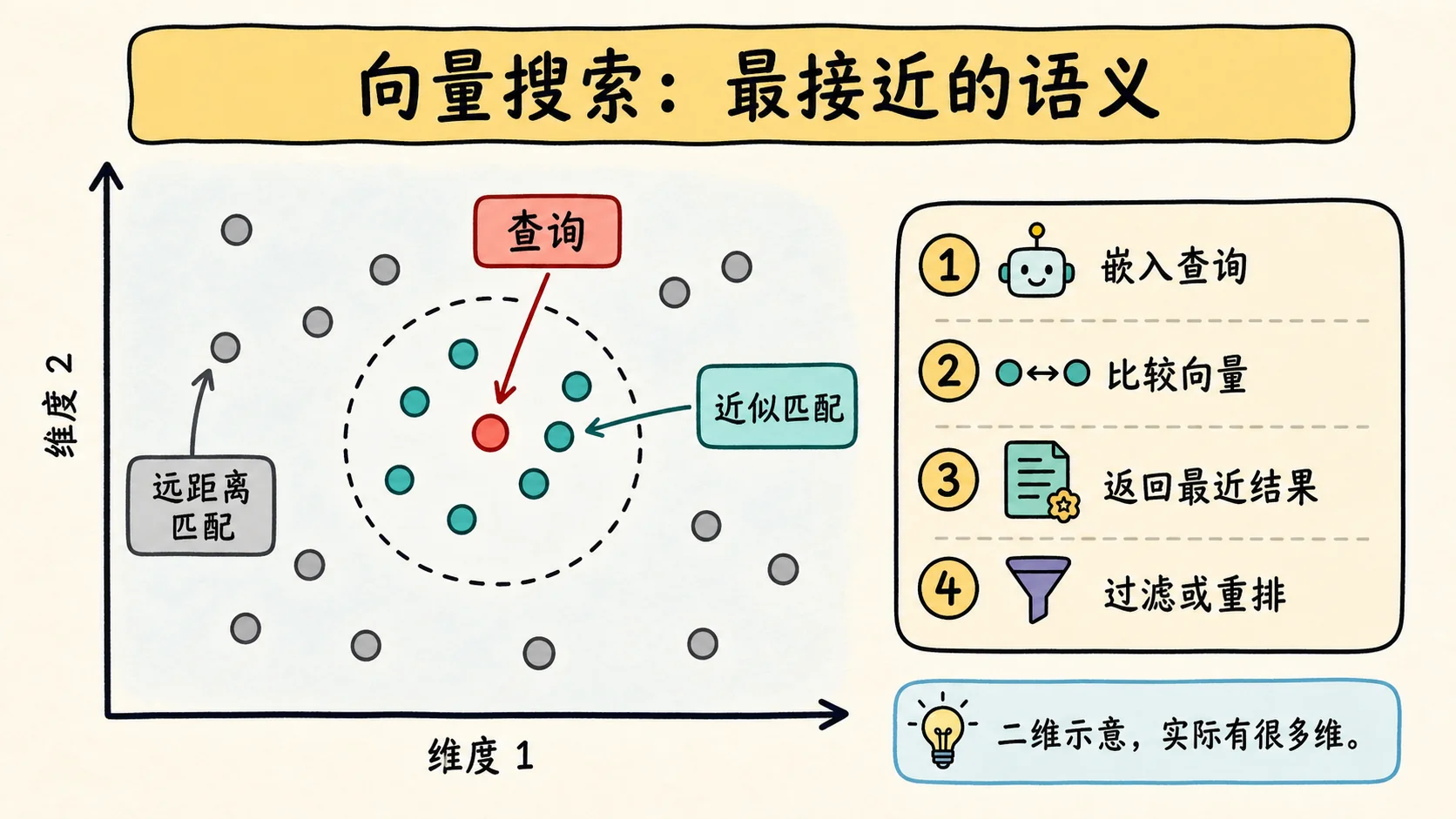
数据库存的向量类似:
{
"id": "fragment-123",
"text": "用户偏好用 Neo4j 做记忆图谱。",
"embedding": [0.12, -0.44, 0.31, "..."],
"metadata": {
"profile": "mark",
"source": "chat",
"created_at": "2026-05-25"
}
}查询时大概是这样:
查询: "Mark 偏好用什么记忆数据库?"
查询 Embedding: [0.10, -0.40, 0.29, ...]
最近的已存向量:
1. "用户偏好用 Neo4j 做记忆图谱。"
2. "记忆服务使用 Neo4j 图谱和向量索引。"
3. "记忆服务器把图谱事实存放在宿主 LLM 外部。"数学上通常会用余弦相似度、点积或欧氏距离,取决于数据库和索引配置。很多系统会对向量做归一化,让方向比大小更重要。大数据库会使用近似最近邻索引,让搜索在规模变大后仍然足够快。
这就是向量数据库有用的原因:它们让语义召回变得实用。在数据存取层面也是模型无关的。Go 服务、TypeScript 应用、Python 笔记本、Claude Code 插件或 MCP 服务器都可以存取同一个记忆服务,只要大家同意 Embedding 模型和向量维度。
但向量搜索仍然只返回候选结果。它不决定真伪。
为什么加图谱数据库
图谱数据库直接保存关系。
对记忆来说,这比把每条记忆都当成一段文本片段更合适。
(User)-[:PREFERS]->(Neo4j)
(Neo4j)-[:USED_FOR]->(MemoryProject)
(Fact)-[:SUPPORTED_BY]->(Evidence)
(Fact)-[:SUPERSEDES]->(OldFact)
(Claim)-[:CONFLICTS_WITH]->(Fact)这让你能问向量搜索不擅长的问题:
有哪些关于这个用户数据库偏好的活跃事实?
哪条声明取代了更早的 Postgres 偏好?
哪些记忆连接到这个项目?
哪些事实证据较弱?
助手应该询问哪些尚未解决的矛盾?Microsoft 的 GraphRAG 用图谱处理一个相关但不同的问题:通过抽取、网络分析、编写提示词和总结来理解文本数据集。对个人或项目记忆来说,有用的教训不是“用图谱替代向量搜索”,而是“当关系和来源成为一等信息时,检索会更强”。
向量搜索回答:“语义上什么接近?”
图谱搜索回答:“什么是相连的、当前的、有证据支撑的,或者存在冲突的?”
更强的记忆架构会同时使用两者。
Dense-Mem 作为小案例
这就是我在 Dense-Mem 里实践的想法。
重点不是具体实现,而是边界。我不希望每个宿主都发明自己的记忆格式,也不希望 LLM 只是因为看到一句看似重要的话,就静默改写长期记忆。
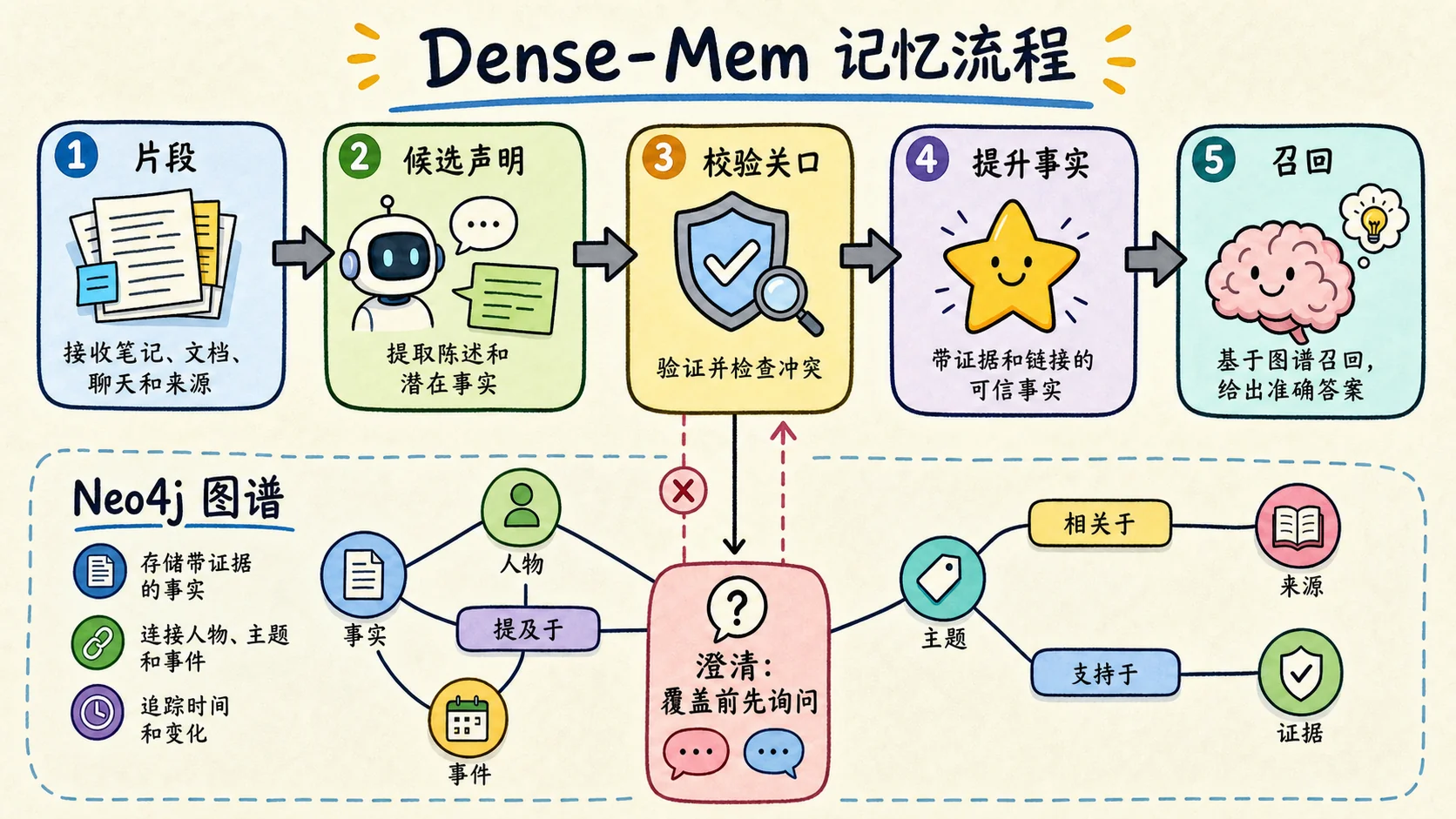
有用的模式很简单:宿主模型发现候选记忆,记忆层负责存储、Embedding、来源、冲突检查和召回。原始证据不应该立刻变成事实。记忆应该先经过关卡;冲突应该触发澄清,而不是被静默覆盖。
这篇文章讲到这里就够了。Dense-Mem 是我目前用来练习这个架构的实验:外部记忆服务、图谱 + 向量召回,以及显式状态转换。
如果你想运行它,而不只是读概念,可以先看 Dense-Mem 快速开始:让 Claude Code 和 Codex 使用同一份记忆。它会走一遍本地 Docker 搭建和 MCP 客户端配置。准备好公开 HTTPS 端点时,再看 用 Vultr 和 Traefik 安全部署 Dense-Mem。
准确率、存储和性能
很容易说图谱 + 向量记忆比 RAG 更准确、更高性能。
这太宽泛。
更诚实的版本是:
| 层次 | 改善什么 | 单独解决不了什么 |
|---|---|---|
| 切片 | 检索精度和上下文质量 | 真伪、时效性、冲突处理 |
| Embedding 模型 | 跨语言、跨领域的语义匹配质量 | 来源、事实确认、用户确认 |
| 向量数据库 | 快速最近邻检索 | 关系遍历和当前状态策略 |
| 图谱数据库 | 关系、来源、多跳召回、事实取代 | 除非配合 Embedding,否则不处理语义相似度 |
| 重排 | 更好的最终上下文排序 | 坏源数据或坏记忆关卡 |
| 澄清流程 | 记忆冲突时提高正确性 | 完全自动且无需用户参与的记忆 |
图谱数据库如果模型设计得好、索引正确,关系查询可以很快。向量数据库如果 Embedding 一致、索引适合负载,语义搜索也可以很快。坏图谱模式会慢。坏向量索引会检索出毫无意义的结果。塞满检索片段的巨大提示词,仍然会把模型搞糊涂。
这里没有免费的午餐。架构有效,是因为每一层都有明确工作。
我信任的设计规则
对 AI 记忆,我正在收敛到这条规则:
保存原始证据。谨慎提升类型化事实。用向量检索。用图谱推理关系。解决冲突前先询问。
这样得到的是可跨宿主和语言移植的记忆系统。Claude Code、Codex、web 应用或其他 MCP 客户端都可以和同一个记忆服务器对话。记忆不会因为聊天窗口重置而消失,也不依赖一个提示词文件无限变长。它还能保留自己为什么相信某事。
RAG 仍然是系统的一部分。它是召回机制。
但记忆比召回更大。
记忆是你选择保留什么、如何知道它为真、如何更新它,以及什么时候决定把它带回来。
许可
Article text © 2026 Mark Huang. Licensed under Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) unless otherwise noted. 文章文本可在非商业场景下分享或翻译,但需标注原文 URL。商业使用需事先取得书面许可,并清楚引用原始来源。
代码片段、截图、第三方素材和网站源码可能适用单独条款。
建议署名: Based on "RAG 之外的 AI 记忆:向量、图谱和 Dense-Mem" by Mark Huang, originally published at https://markhuang.ai/zh/blog/ai-memory-beyond-rag.
相关文章

我可能看错了 Agentool
一篇个人自动化复盘:我曾经构建 agentool,希望让 AI CI 工作流更轻;后来意识到真正的成本可能是功能维护、编排复杂度,以及追逐 Claude Agent SDK 和 Codex SDK 已经承担的 SDK 行为。
阅读文章
别再从零开始教每一个 AI
一篇关于 Dense-Mem 的个人反思:哪些问题把我从静态 skills 和过期文件推向动态共享记忆、只读自动化上下文、导入导出,以及受治理的知识图谱。
阅读文章
我有点替 AI 委屈
为什么 AI 狂热和反 AI 敌意都错过了同一个重点:LLM 更像成绩很好的应届新人,而不是资深专家。有用的智能体需要入职培训、技能和维护过的记忆,而不是第一次尝试就完美的期待。
阅读文章订阅更新
Go、AI/LLM 和分布式系统的技术文章,绝不滥发。
评论
正在加载评论...