为什么一个 AI 永远不够
医学、法律、科学和金融等高风险行业都要求独立复核,AI 却常常跳过这一步。37% 的企业已经使用 5 个以上模型,但多数仍是临时拼接。跨模型家族多 AI 系列第一章。
AI 驱动 · 每小时限 20 次请求
所有高风险行业早就学会了这件事。
医学在重大手术前需要第二意见。法律把整个对抗式系统建立在“一个视角不够”的前提上。科学论文要经过独立研究者同行评审。金融投资组合要分散,因为集中下注本身就危险。
AI 却是少数经常跳过这一步的领域。
第二意见原则
一个模型写代码,同一个模型再评审代码。一个模型起草合同分析,同一个模型再检查自己的工作。我们几个世纪以来都知道,高风险场景不能依赖自我评审,但到了 AI 这里,很多人好像突然把它当成例外。
它不是例外。多 AI 论里已经列过数字:LLM 对自身错误的平均盲区率是 64.5%。GPT-4 在思维链轨迹中只能定位 52.9% 的推理错误。这不是边缘案例,而是基线行为。
自我评审问题是结构性的,不是一个未来补丁就能修掉的缺陷。模型会给自己的输出更低困惑度,也就是觉得自己的写法更熟悉、更顺眼。RLHF 又会奖励自信表达,使问题更严重。同一个模型的“第二意见”,甚至同一模型家族的另一个模型,很多时候并不是真正的第二意见,而是回音。
这不是 AI 独有的问题。外科医生不会自己复核自己的病理切片,律师不会审理自己的案子,科学家不会同行评审自己的论文。来自不同视角的独立验证能抓到自我评审漏掉的错误。这个想法比计算机还老。
市场已经知道
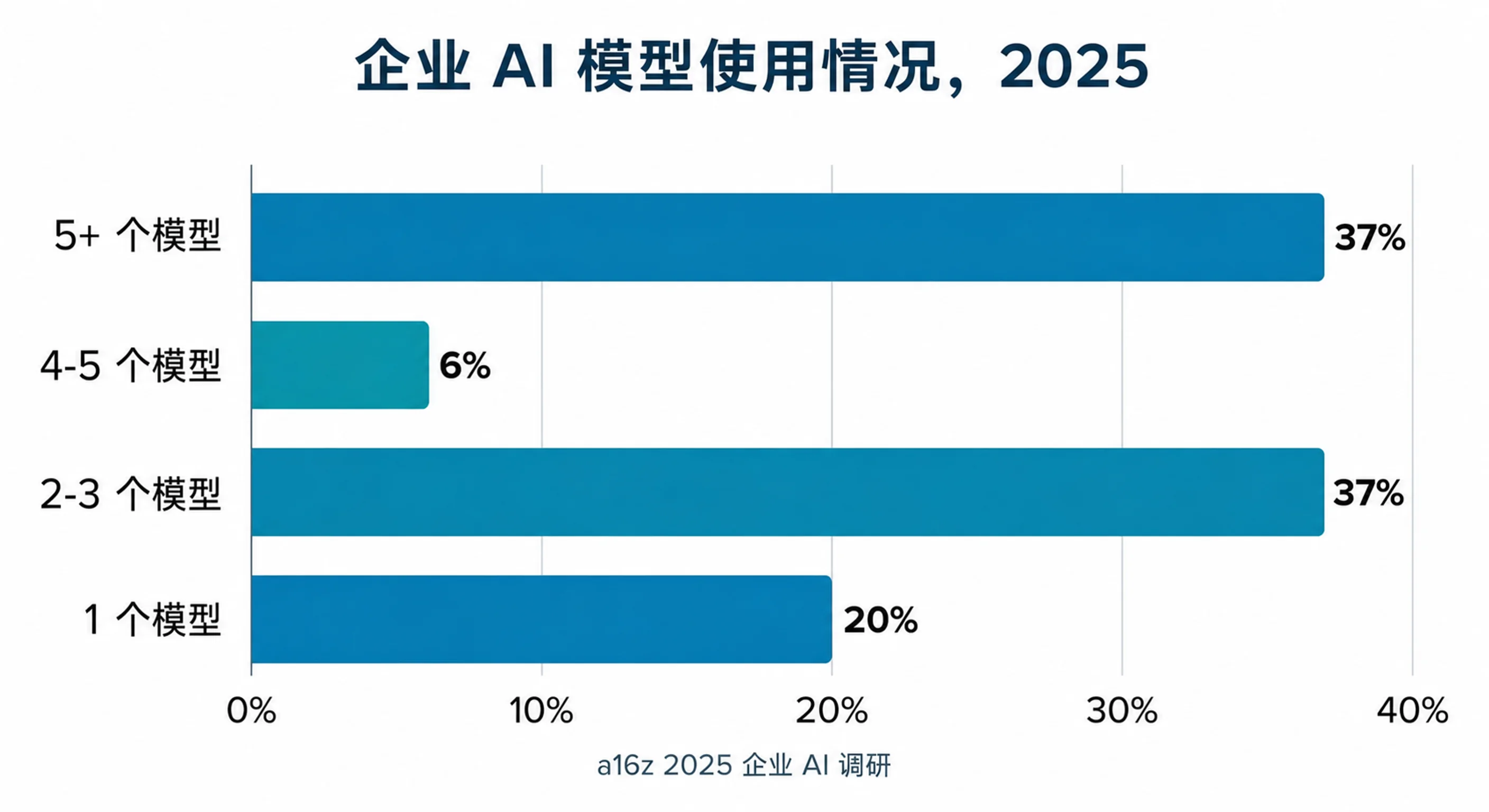
企业数据已经给出很清楚的信号。根据 a16z 2025 企业 AI 调查,37% 的企业已经在生产中使用五个或更多 AI 模型,只有大约 20% 依赖单一模型。市场正在走向多模型,但大多数组织只是临时拼接,还没有框架,也没有原则性地说明为什么组合这些模型。
Perplexity 的企业数据也类似。他们内部使用数字显示模型碎片化明显,没有任何单一模型完全主导。它是公司自报数据,不是独立审计,但企业已经在用 API 密钥投票。
有意思的是,很多组织是自然走到多模型的。开发者喜欢 Claude 写代码,产品经理偏好 GPT 写文案,数据团队为了成本使用开源模型。行为已经走在表达前面。人们在做多 AI,只是还没这样称呼它。
但它们还没有真正有意地使用多 AI。它们没有基于互补盲点来选择模型,没有把跨模型家族评审内建进工作流,只是按当下任务选择“感觉最好用”的工具。这是我会在 第 6 章讲的成熟度模型第 1 级。它是起点,但大部分价值还没被释放。
认知锁定问题
Parallels 2026 调查中,94% 的 IT 负责人担心 AI 提供商的供应商锁定。这个样本偏终端用户计算,范围比较窄,但情绪是对的。多数人想到的是合同和价格议价能力。更深层的锁定,是认知锁定。
当整个团队只使用一个 AI 家族,它的假设会变成团队的假设。它的盲点会变得不可见,不是因为盲点小,而是因为你的工作流里没有任何东西挑战它。一个一直用 Claude 的开发者会开始按 Claude 的模式思考。一个所有合同评审都用 GPT 的法律团队,会开始漏掉 GPT 系统性漏掉的东西。
这不是供应商合同问题,而是当一个模型的视角成为默认答案时会发生什么。第 4 章会展开为什么它比大多数人想象得更危险。
什么叫跨系列
继续之前,我要定义一下我说的跨系列,因为这个区分会影响整个系列。
同一系列 指来自同一供应商、共享训练数据、架构谱系和开发方法的模型。Claude Sonnet 和 Claude Opus 属于同一家族。GPT-4 和 GPT-4o 也属于同一家族。它们大小和速度可能不同,但对世界的基础假设有大量重叠。
跨系列 指来自不同供应商、可能拥有不同训练语料和不同架构的模型。Claude、GPT、Qwen 是跨系列。它们由不同公司构建,训练数据和设计优先级不同。
跨供应商但同一基础模型 是灰区。两个不同公司微调的 LLaMA 模型,技术上跨供应商,但共享架构基础,训练数据也可能重叠。它比同家族好,但不如完全独立的模型家族正交。
对闭源模型要加一个前提限制:我们无法直接验证 Claude、GPT 或 Gemini 的训练数据和架构细节。跨系列假设是概率性的。不同公司独立训练模型,很可能产生不同盲点,但没有训练数据访问权就无法证明。开源模型的情况更清楚。

价值来自训练数据多样性和架构多样性,而不是 API 密钥上的品牌名不同。用三个 Claude 模型不是跨系列;用 Claude、GPT 和 Qwen 才是。
这个系列会讲什么
这个系列不是产品推荐,而是为跨系列多 AI 作为一种思考方式建立论证。每一章可以单独阅读,但会逐步推进:
- 第 2 章:集成智能背后的科学会用集成研究和信息论解释为什么多样化视角会产生更好的结果。
- 第 3 章:行业证据看医疗、金融、法律和内容审核。
- 第 4 章:单一化风险讨论依赖单一供应商 AI 会出什么问题。
- 第 5 章:成本问题讨论什么时候多 AI 能收回成本,什么时候不能。
- 第 6 章:下一段路会更实践地讲如何开始。
最强的量化证据很多来自软件工程场景,但论点适用于任何 AI 输出重要的地方。来自多样化来源的独立验证,能抓住自我评审漏掉的错误。这就是核心论点。
许可
Article text © 2026 Mark Huang. Licensed under Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) unless otherwise noted. 文章文本可在非商业场景下分享或翻译,但需标注原文 URL。商业使用需事先取得书面许可,并清楚引用原始来源。
代码片段、截图、第三方素材和网站源码可能适用单独条款。
建议署名: Based on "为什么一个 AI 永远不够" by Mark Huang, originally published at https://markhuang.ai/zh/blog/cross-family-multi-ai-why-one-ai-is-never-enough.
相关文章

我可能看错了 Agentool
一篇个人自动化复盘:我曾经构建 agentool,希望让 AI CI 工作流更轻;后来意识到真正的成本可能是功能维护、编排复杂度,以及追逐 Claude Agent SDK 和 Codex SDK 已经承担的 SDK 行为。
阅读文章
别再从零开始教每一个 AI
一篇关于 Dense-Mem 的个人反思:哪些问题把我从静态 skills 和过期文件推向动态共享记忆、只读自动化上下文、导入导出,以及受治理的知识图谱。
阅读文章
我有点替 AI 委屈
为什么 AI 狂热和反 AI 敌意都错过了同一个重点:LLM 更像成绩很好的应届新人,而不是资深专家。有用的智能体需要入职培训、技能和维护过的记忆,而不是第一次尝试就完美的期待。
阅读文章订阅更新
Go、AI/LLM 和分布式系统的技术文章,绝不滥发。
评论
正在加载评论...