1+1 假说:能否把编程问题拆到任何 LLM 都能做?
每个 LLM 都会算 100×100,每个编程 LLM 都能重命名变量。但可靠性从哪里开始断裂?工程化 harness 能不能把边界往前推?本文讨论剩余解空间熵、测试先行契约、分层防御架构,以及为什么盲目共识会失败,而验证式搜索有效。
AI 驱动 · 每小时限 20 次请求

每个 LLM 都会算 100 乘以 100。每个会写代码的 LLM 都能重命名变量。但如果让 Qwen 3.5 根据验收标准实现一个功能,大约有一半的概率你会得到自信但错误的代码。同一个任务交给 Opus 或 GPT-5.4,通常就可靠得多。
我运行 多 AI 流水线 已经有一段时间。强模型效果很好。但把较弱模型换进去,比如 Qwen 3.5、GLM-5、MiniMax M2.5,流水线就会卡住。不是因为这些模型不会写代码。它们显然会。只是输出不够可靠,不能放进自动化流水线里信任。
这让我开始想:如果存在一个从“永远正确”(简单算术)到“经常错误”(复杂功能)的光谱,可靠性到底在哪个位置断崖式下降?更重要的是,我们能不能通过工程脚手架推动边界,而不是只等更强模型?
我把它叫作 1+1 假设。不是因为软件像算术一样可加(显然不是)。这个假设更窄:对任何具备编码能力的模型,都存在一个任务粒度,让解空间窄到模型可以可靠输出。工程挑战是找到并抵达这个粒度。
能力断崖
我的流水线会把任务拆成大约 50 行代码的单元。强模型处理得不错。但弱模型失败的位置并不是我预期的地方。实现本身通常还不错。真正坏掉的是上游语义工作:模型能否综合调查结论?能否判断需求是否完整?能否判断代码是否真正符合审查背后的意图?
这些阶段的解空间很宽。对“这段代码是否符合验收标准”没有唯一正确答案。失败点是判断,而不是打字。
所以真正的问题不是“弱模型能不能写代码”,而是“我们能不能把流水线的每个阶段都压窄到模型能力几乎不重要”。
不是代码行数,而是残余解空间熵

我最先尝试的是把单元变小。如果 50 行对 Qwen 太多,也许 10 行可以。结果帮助不大。一个需求含糊的 10 行函数,比一个契约清晰的 50 行函数更容易失败。
决定性因素不是代码行数,而是我称为残余解空间熵的东西:当你把所有条件都说明后,还剩多少种有效实现?如果答案基本只有一种,弱模型也能做对。如果答案有几十种,强模型也可能选错。
三种技巧可以压缩这个熵。
第一,接口契约。一个带类型、前置/后置条件和显式边界情况的函数签名,会把解释空间压到很小。模型填函数体,而不是做设计。
第二,测试用例。预先写好的测试把“实现这个功能”变成“让这些断言通过”。这是一种完全不同的任务,更接近约束满足,而不是开放式生成。
第三个让我意外:算法提示。一句话,比如“使用 bcrypt.compare 验证密码”或“用滑动窗口迭代”,可以把无限多种实现压到一两种。用最少的干预获得最大的可靠性提升。
一个实用收敛测试:让弱模型对同一任务跑五次。如果其中四次产生语义等价代码,任务已经足够窄。如果五次得到五种不同方法,解空间熵仍然太高。
分工
这带来一个令人不安的事实:你仍然需要某个地方有强模型。分解本身,也就是决定怎么拆问题、写契约、设计测试用例,正需要弱模型不擅长的推理。
但这不是假设失败,而是杠杆。
一次 Opus 调用生成 50 个契约。50 次 Qwen 调用填实现。强模型推理一次,弱模型抄写很多次。比所有任务都跑强模型便宜得多,而且契约可以在重试之间复用。
研究文献里有类似名字。Burns et al. (2023) 称之为“弱到强泛化”:强监督者通过仔细的规格说明,从弱模型里引出可靠表现。这里的机制正是如此:强模型当架构师,弱模型当施工者。
经济账也成立。强模型 token 用来写规格说明,弱模型 token 用来写代码。规格说明成本按单元类型固定,实现成本随尝试次数增长。只要弱模型能在几次内成功,总成本就更低。
不只实现,上游语义阶段也一样
那我前面说的真正失败点怎么办?调查、需求、代码审查、拆解这些上游阶段,弱模型也能处理吗?
我做了第二轮研究,答案是:可以处理一部分,前提是重构这些阶段。
两种技巧有效,原因不同。
多视角拆分会压窄判断空间。不要问一个模型“审查这段代码”,而是给十个模型各自一个聚焦视角:“检查 SQL 注入”“评估错误处理”“验证 API 契约”。每个聚焦查询都窄到弱模型可以处理。然后机械地合并发现:合并、去重、按严重度排序。这正是多 AI 流水线已经在做的事,但这里的洞见是:它有效,是因为范围被压窄,而不只是因为模型多样性。
递归拆解会在每一层压窄推理范围。不要直接问“把这个 500 行功能拆成原子单元”(难),而是“把这个功能拆成 3 到 5 个主要部分”(容易),再把每个部分拆成 3 到 5 个子部分(更容易),重复直到原子单元。Least-to-Most Prompting 和 Decomposed Prompting 的研究支持这一点。更小的子问题确实更容易。
问题是,朴素的递归拆解会放大错误。一个糟糕的顶层拆分会污染下面所有东西。它只有在每一层都有类型化输出模式、能本地验证,而且系统可以回退或尝试其他拆解时才有效。这本质上接近 Tree of Thoughts 方案。
真正可用的组合方案是:递归拆解负责结构,多视角拆分负责每层覆盖,结果机械合并,只把冲突升级。综合步骤不需要聪明,需要结构化。
分层防御
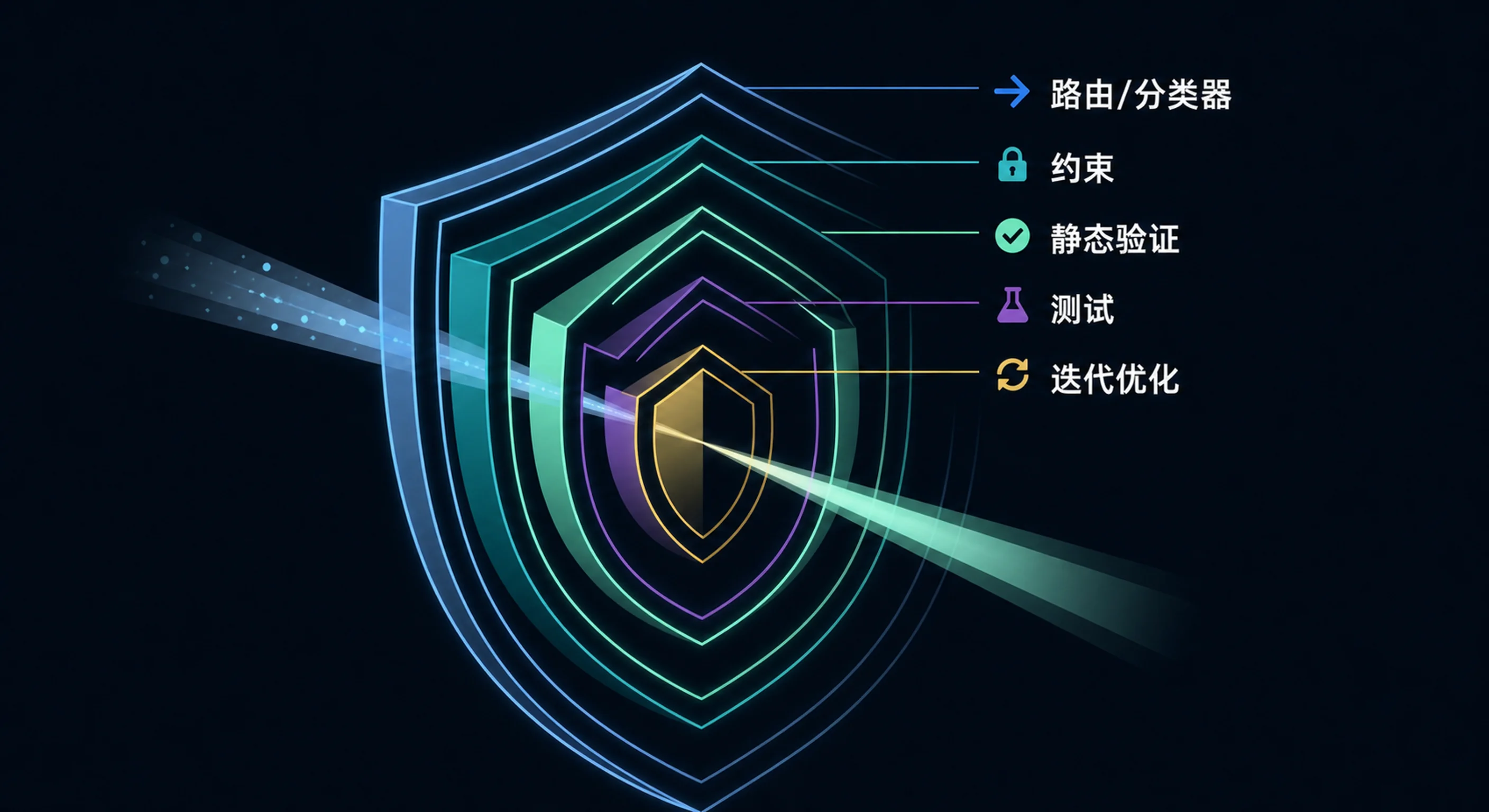
为了测试这些想法,我跑了一场多 AI 辩论:11 个模型、4 个家族(Claude Opus、Qwen 3.5、Kimi K2.5、GLM-5、Qwen 3 Max),两轮对抗讨论。它们独立收敛到同一个五层架构:
| 层 | 目的 | 示例 |
|---|---|---|
| 能力分类器 | 把任务路由到匹配模型层级 | 新算法 → 强模型;CRUD → 弱模型 |
| 结构化约束 | 生成前压窄解空间 | 契约、模式、算法提示、检查清单 |
| 静态验证 | 最便宜的关卡,抓表层错误 | 类型检查、静态检查、模式验证 |
| 测试执行 | 功能验证 | 预写测试作为判定器 |
| 迭代修正 | 错误反馈循环 | 生成 → 测试 → 送入错误 → 重试(最多 3 次) |
最小可用栈取决于你的可靠性目标:
| 目标 | 最小栈 |
|---|---|
| ~80%(内部工具) | 契约 + 静态关卡 |
| ~90%(面向客户) | + 迭代修正 |
| ~95%+(关键系统) | + 能力分类器 + 强模型审查 |
迭代修正特别值得强调。弱模型第一次可能只有 60% 正确,但你把具体测试失败和错误信息给它看,第二次会跳到 85%。这不是新东西,本质上是现代版 counterexample-guided inductive synthesis (CEGIS),一个在程序综合中有效了几十年的技术。LLM 版本只是更便宜、更灵活。
盲目共识错在哪里
我最初的一个假设是大量采样共识:让五个弱模型做同一任务,用多数投票选结果。token 成本低,让这在规模上看起来可行。
辩论里的每个模型都反对这个想法。全票反对。讽刺的是,这些本来会被该方法使用的模型,自己论证了它不该被使用。
原因是 Condorcet's jury theorem。多数投票只有在错误独立时才提高可靠性。但模型都训练在相似的 GitHub 和 Stack Overflow 语料上,会共享系统性盲点。五个 Qwen 实例不给你五个独立意见,而是同一个意见采样五次,只带一点差异。
但这里有个细节我差点漏掉。盲目共识(多数投票,没有判定器)会失败。带验证的搜索(大量样本,强选择器)能工作。AlphaCode 生成成千上万个候选,然后用测试执行过滤。Codex 显示 pass@100 明显超过 pass@1。Brown et al. (2024) 发现,当你有验证器时,推理时扩展是有效的。
这个区别很重要。共识衡量一致性,不衡量正确性。判定器直接衡量正确性。有足够强的判定器(测试、静态分析、执行),大量采样就变成搜索策略,而不是投票策略。
诚实的限制
我也要指出自己的盲点。产生这些发现的多 AI 辩论,本身可能有认知上的同质化倾向。模型共享训练数据、基准测试常识和常见论文。它们的“普遍收敛”可能只是来自重叠知识库的相关性一致,也就是我们在大量采样共识里指出的同一类失败模式。
所以请把这些发现当作假设,而不是结论。
即便如此,失败模式真实存在,值得列出来:判定器失败(弱测试带来虚假信心)、接口泄漏(被分解单元之间隐藏耦合)、分布不匹配(模型会普通 Python,却不会小众 API)、拆解错误(错误抽象边界让每个下游部件局部正确但整体错误)、经济账问题(到某个点,分解成本超过直接用强模型)。
可处理比例高度依赖领域。CRUD 和数据转换中,也许 80% 的任务足够窄。安全关键代码或新算法,也许 60%。全新架构的答案可能是“用强模型”。
还有启动问题。总得有人,人类或强模型,写出好契约。这个假设减少强模型使用,而不是消灭它。
这意味着什么
1+1 假设的可防守版本是:对目标范式有非零覆盖的模型,只要加入足够强的判定器,可靠性就会变成搜索空间工程问题。
不要试图把弱模型变聪明。把解空间变窄,把判定器变强。
工程脚手架和模型一样重要。也许更重要。
许可
Article text © 2026 Mark Huang. Licensed under Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) unless otherwise noted. 文章文本可在非商业场景下分享或翻译,但需标注原文 URL。商业使用需事先取得书面许可,并清楚引用原始来源。
代码片段、截图、第三方素材和网站源码可能适用单独条款。
建议署名: Based on "1+1 假说:能否把编程问题拆到任何 LLM 都能做?" by Mark Huang, originally published at https://markhuang.ai/zh/blog/the-1-plus-1-hypothesis.
相关文章

我可能看错了 Agentool
一篇个人自动化复盘:我曾经构建 agentool,希望让 AI CI 工作流更轻;后来意识到真正的成本可能是功能维护、编排复杂度,以及追逐 Claude Agent SDK 和 Codex SDK 已经承担的 SDK 行为。
阅读文章
别再从零开始教每一个 AI
一篇关于 Dense-Mem 的个人反思:哪些问题把我从静态 skills 和过期文件推向动态共享记忆、只读自动化上下文、导入导出,以及受治理的知识图谱。
阅读文章
我有点替 AI 委屈
为什么 AI 狂热和反 AI 敌意都错过了同一个重点:LLM 更像成绩很好的应届新人,而不是资深专家。有用的智能体需要入职培训、技能和维护过的记忆,而不是第一次尝试就完美的期待。
阅读文章订阅更新
Go、AI/LLM 和分布式系统的技术文章,绝不滥发。
评论
正在加载评论...