行业证据:医疗、金融、法律以及更多场景
多模型 AI 已经进入医疗诊断、金融风险管理、法律分析和内容审核的主流实践。本文整理四个行业的证据,以及它们对跨模型家族 AI 采用的意义。跨模型家族多 AI 系列第三章。
AI 驱动 · 每小时限 20 次请求
第 2 章里的集成科学预测,多样模型组合应该优于单模型。但预测很便宜。现实行业里的证据长什么样?
先放一个透明说明:跨系列多 AI 最强的量化证据来自软件工程场景,比如 GitClear、Veracode、Stanford、Blueprint2Code。下面讲的行业证据是真实的,但很多是类比性的。医疗、金融、法律现在更多使用多模态集成和领域特定模型组合,而不是我描述的那种直接跨系列 LLM 路由。底层思想相同:多样模型视角提升结果。实现方式不同。我会区分每个行业实际在做什么,以及我在推断什么。
医疗
医疗是风险最高、多模型 AI 证据也最强的行业之一。
PNAS 关于人类与 AI 混合集体的研究发现,医生与多个 LLM 协作时,在鉴别诊断上超过了单个医生、独立 LLM 和单系统方案。不同视角捕捉不同模式,诊断准确率高于任何单一专业来源。
LLM 之外,多模态 AI 架构在医学影像里已经很常见。把 CT 图像模型(例如 ResNet-50 这类架构)和临床报告模型(例如 RoBERTa 这类语言模型)组合起来的集成,在疾病分类上持续超过单模型。后期融合策略,也就是保留不同模态专属模型并聚合输出,而不是把一切硬塞进单一架构,已经是放射学、病理学、基因组学里的常见方法。
医疗和跨系列多 AI 的关系是类比:这些是不同类型的模型(视觉和语言),而不是同一类型下的不同家族。但机制一样。不同数据训练出的模型会抓到不同模式。CT 模型看到临床报告看不到的结构异常,报告模型抓到影像模型看不到的诊断线索。合在一起比任一模型单独使用更准确。
如果视觉模型加语言模型能在诊断里抓到更多错误,那么不同 LLM 家族的组合,在任何准确性重要的领域里,也应该更容易捕捉单一家族漏掉的问题。
金融
金融比几乎任何行业都更早使用集成方法。投资组合理论本质上就是集成论证:分散到不相关资产,可以降低风险,而不会等比例降低收益。相同数学也适用于 AI 模型选择。
Li 与 Tang (2024) 构建了一个自动化波动率预测系统,组合了五种算法。这个集成在 S&P 100 的所有时间区间上都稳定超过单个模型。Gu、Kelly 与 Xiu (2020) 在 The Review of Financial Studies 发表的研究显示,机器学习集成在 30,000 只美国股票上超过传统回归模型。
Financial Stability Board 2024 报告明确把 AI 服务提供商集中度视为金融行业的系统性漏洞。它们的担忧和投资组合分散的逻辑一致:如果大量金融分析流经同一个 AI 家族,这些模型就会共享同一组盲点。所有人得到同一个错误答案,而且因为每个人的模型都同意,没人发现。监管者花了几十年试图在银行体系中降低的集中风险,现在正在 AI 模型选择里重新出现。
金融早就理解:独立且不相关的视角会降低风险。集成研究说明,这个规律作用于 AI 模型时同样成立。
法律
法律行业的 AI 采用正在加速。Thomson Reuters 2025 数据显示,法律 GenAI 使用率同比接近翻倍,45% 的律所已经在使用 AI 或集中规划 AI 采用。对一个传统上很保守的行业来说,这个速度相当惊人。
为不同法律任务使用多个 LLM 的趋势正在增长。合同分析、案例研究、文档审查、合规检查有不同特征,没有任何单模型能在所有任务上都最好。先进法律 AI 框架开始把检索增强生成、知识图谱、多种模型架构(GPT-4、LLaMA-3 等)组合起来,分别处理不同任务类型。用于法律审查的多智能体 LLM 系统也正在形成独立研究方向。
这很自然地让人联想到交叉询问。法律里的对抗式程序之所以存在,是因为单一视角不足以保障司法公正。你不会只相信一位律师对事实的解释,也不会不经挑战就接受一个专家的分析。整个系统都假设独立、对抗式审查会比未经挑战的分析产生更好结果。
AI 辅助法律工作也应该遵循同样逻辑。一个模型做合同分析,再由另一个家族的模型评审,比同一个模型检查自己的工作更可能发现问题条款或遗漏义务。第 2 章里的回音室研究直接适用:同系列审查有信念固化风险,审查模型会强化而不是挑战原始模型的解释。
内容审核
内容审核可能是单模型方案为什么无法规模化的最好例子。错误有两个方向:误杀会压制合法表达,漏放会放过有害内容。
参与 Digital Trust & Safety Partnership (DTSP) AI 工作组的大型平台,包括 Google、Meta、Microsoft、Pinterest、Reddit、TikTok 等,都建议把多个自动化工具与人工审查组合起来。它们的最佳实践指南承认,在全部内容类型、语言和文化语境上,没有任何单模型能达到可接受准确率。
多模态 AI 系统把计算机视觉、音频分析、文本分类、图像识别、自动标记和人工审查结合起来,覆盖面会比任何单一方案更完整。文本分类器可能漏掉图片里的有害内容;视觉模型可能看不到让一张看似无害图片变得有问题的语境。组合起来才能覆盖更多表面。
模式
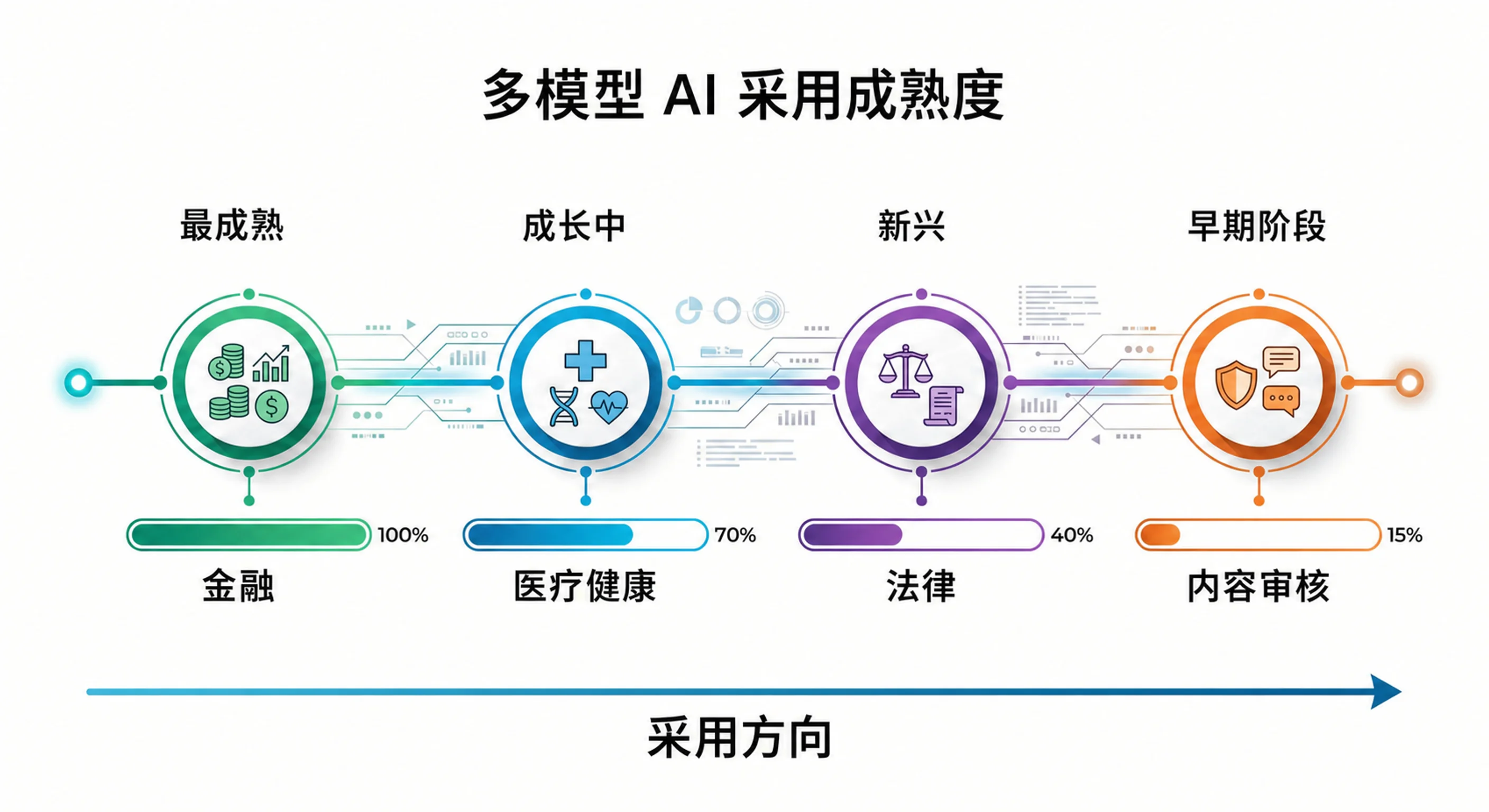
随着 AI 使用成熟、风险提高,组织通常会从单模型走向多模型。这不是绝对规律,不同行业、公司规模、风险偏好差异很大,但趋势很稳定。
金融最成熟,集成方法已经进入核心业务,监管框架也推动提供商多样化。医疗领域正在快速增长,因为诊断准确性要求更高、错误的后果更严重。法律仍处于萌芽阶段,但采用已经几乎同比翻倍。内容审核还比较早,但平台领导者已经得出结论:单模型方案不够。
成熟度梯度和风险一致。错误成本最高的领域,最早转向多模型。只要漏掉错误的代价足够高,多模型系统的额外复杂度就会变成理性投资。
这些行业证据和我主张的跨系列 LLM 路由并不完全一样。它们用的是多模态集成、领域特定模型组合和多架构框架,不一定是不同 LLM 家族互相评审文本输出。但机制相同:不同数据训练出的多样模型视角会抓到不同错误。无论是在放射科把视觉模型和语言模型组合起来,还是在代码审查里把 Claude 和 GPT 组合起来,核心机制都是通过多样性来降低错误之间的相关性。
多模型方案有效的证据已经很强。组织不采用它会发生什么,是 第 4 章 的主题。
许可
Article text © 2026 Mark Huang. Licensed under Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) unless otherwise noted. 文章文本可在非商业场景下分享或翻译,但需标注原文 URL。商业使用需事先取得书面许可,并清楚引用原始来源。
代码片段、截图、第三方素材和网站源码可能适用单独条款。
建议署名: Based on "行业证据:医疗、金融、法律以及更多场景" by Mark Huang, originally published at https://markhuang.ai/zh/blog/cross-family-multi-ai-industry-evidence.
相关文章

我可能看错了 Agentool
一篇个人自动化复盘:我曾经构建 agentool,希望让 AI CI 工作流更轻;后来意识到真正的成本可能是功能维护、编排复杂度,以及追逐 Claude Agent SDK 和 Codex SDK 已经承担的 SDK 行为。
阅读文章
别再从零开始教每一个 AI
一篇关于 Dense-Mem 的个人反思:哪些问题把我从静态 skills 和过期文件推向动态共享记忆、只读自动化上下文、导入导出,以及受治理的知识图谱。
阅读文章
我有点替 AI 委屈
为什么 AI 狂热和反 AI 敌意都错过了同一个重点:LLM 更像成绩很好的应届新人,而不是资深专家。有用的智能体需要入职培训、技能和维护过的记忆,而不是第一次尝试就完美的期待。
阅读文章订阅更新
Go、AI/LLM 和分布式系统的技术文章,绝不滥发。
评论
正在加载评论...