多 AI 论
LLM 会在超过 90% 的情况下确认自己的答案,对自身错误还有 64.5% 的盲区率。跨模型家族的多 AI 流水线,让 Claude 评审 GPT、GPT 评审 Qwen,能打破自我评审的天花板。本文讨论研究、成本和真正有效的做法。
AI 驱动 · 每小时限 20 次请求
每个 AI 模型都有盲区。2025 年的一个基准给了一个数字:LLM 的平均盲点率是 64.5%。它们很难纠正自己输出里的错误,但同样的错误如果被包装成“别人写的东西”,它们反而能发现。GPT-4 在思维链轨迹里只能定位 52.9% 的推理错误,哪怕是很直接的错误也会漏。
这不是下一版模型就会修掉的问题。它是结构性的。用一个 AI 写代码,再用同一个 AI 评审代码,你的审查流程有一部分只是在演戏。

自我评审问题
2025 年一项覆盖 14 个开源模型的研究发现,LLM 不能可靠地发现自己输出里的错误,但能在“他人作品”的语境中发现同样的错误。研究者把原因追到训练数据:普通指令数据集里,自我纠错标记大约每 100 句才出现一次;推理模型数据集里则是 30 到 170 次。模型见过太少“纠正自己”的例子。
还有自我偏好偏差。模型会给自己的输出更低困惑度,也就是觉得更熟悉,并系统性地打更高分。RLHF 又会奖励自信回答,哪怕准确性不足。但当同一段内容被放在全新的上下文里,模型不知道是自己生成的,错误检测会明显改善。研究者称之为“洁净室效应”。
来自同一个模型的第二意见,并不是真的第二意见。模型认得自己的模式,然后确认它们。
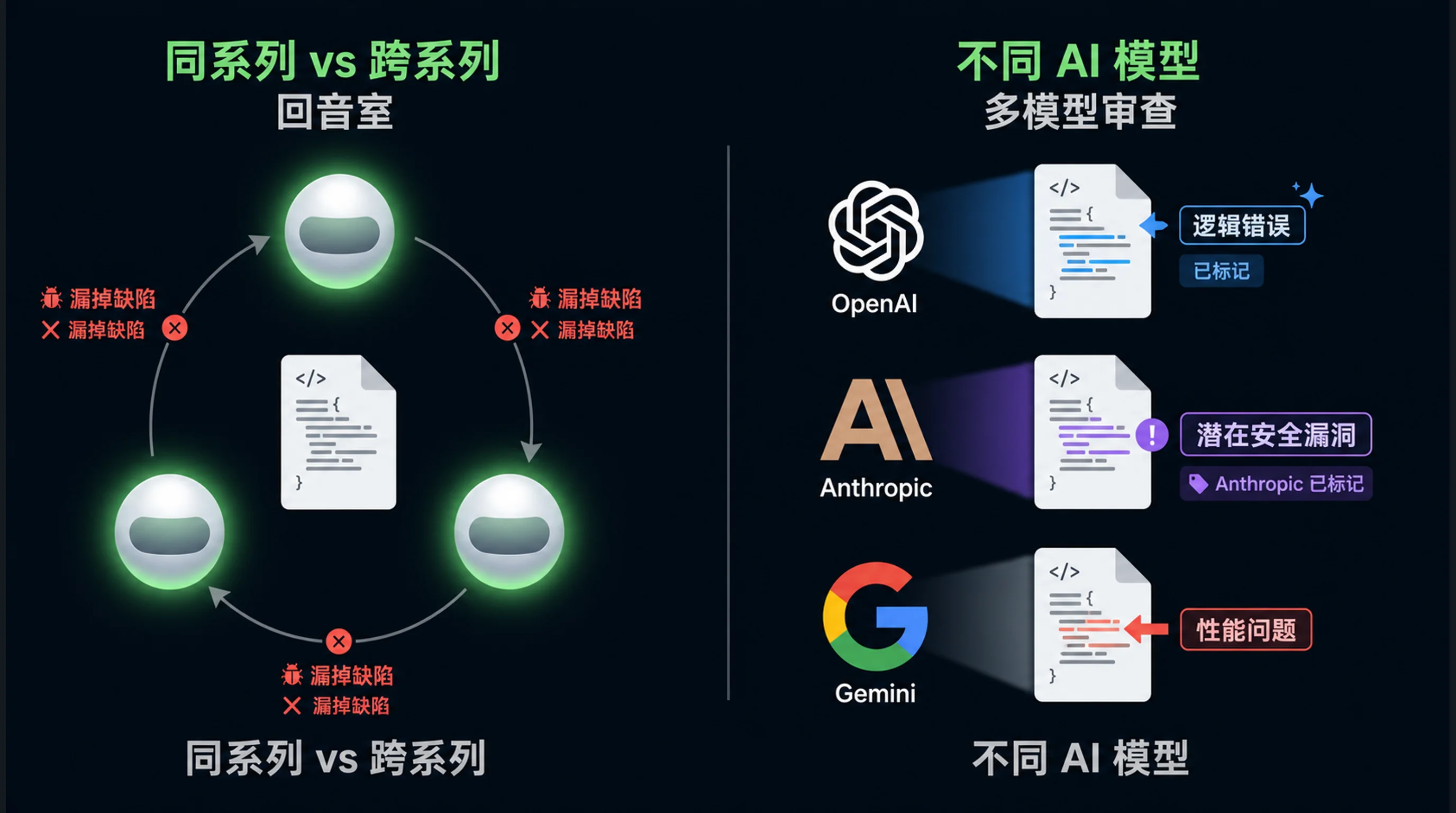
同一家族不是多 AI
这里我想把边界说清楚:让 Claude Sonnet 和 Claude Opus 处理同一个任务,不是我说的多 AI 审查。它们共享训练数据、架构假设和盲点。
回音室研究支持这个判断。2025 年一项多智能体辩论研究发现,当智能体共享同一个模型和训练数据时,辩论会“放大对错误答案的信心,而不是纠正它”。论文把这叫作“信念固化”。这些智能体会强化共同错误,而不是捕捉错误。从众倾向是训练里内建的。当一个 Claude 实例说某个东西正确时,另一个 Claude 实例天然更倾向于同意,因为它们从同一类数据里学来。
另一项多智能体系统研究找到了两个根因:相同训练数据带来的带偏差静态初始信念,以及会放大多数观点的同质化辩论动态,不管多数观点是否正确。
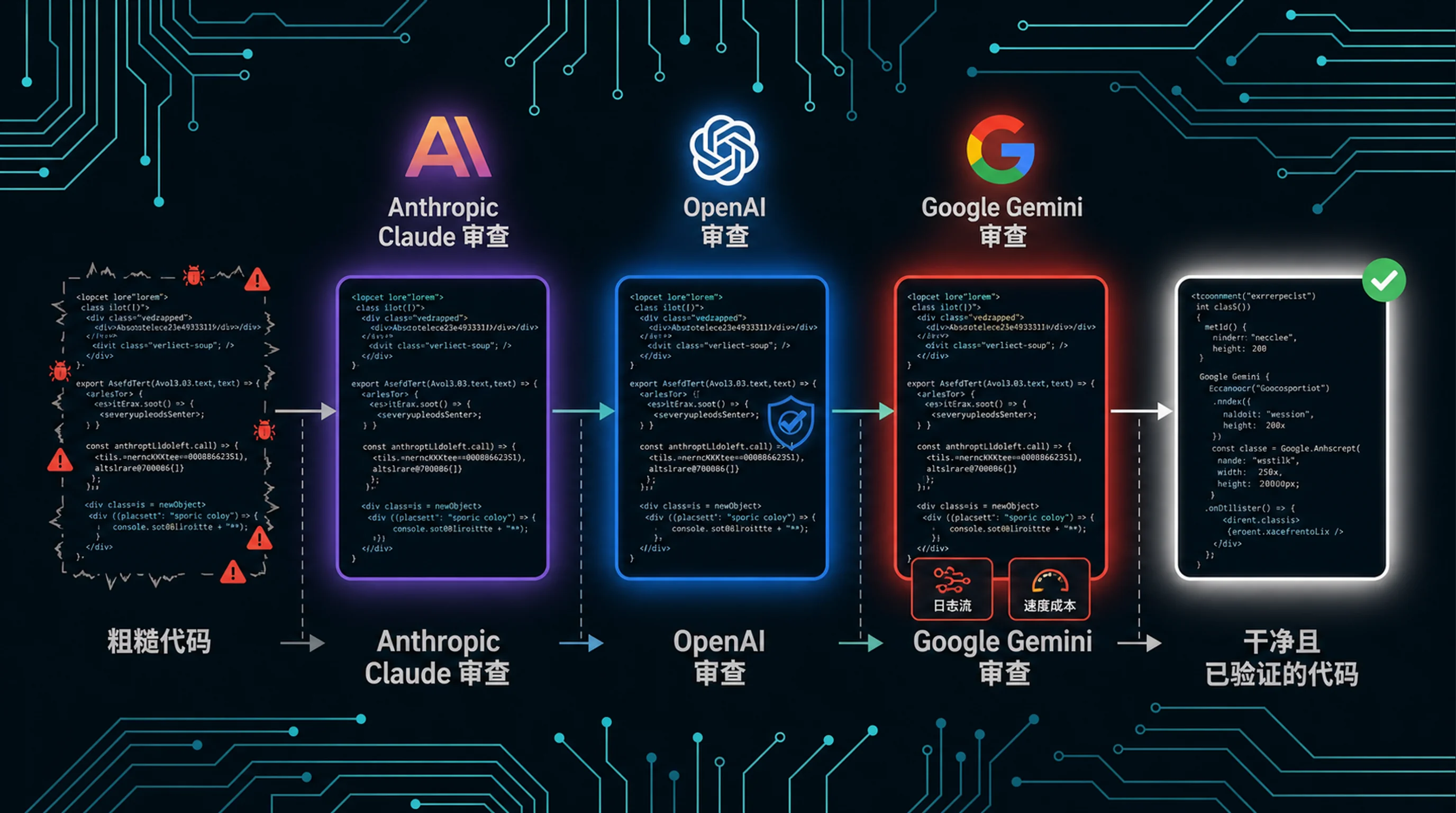
所以我说多 AI 时,特指 跨系列。Claude 评审 GPT,GPT 评审 Qwen。不同训练语料,不同架构假设。盲点重叠的概率会低得多。
研究已经证明什么,我又在推断什么
现有研究强烈说明,多智能体系统在很多场景下优于单个智能体。它还没有直接证明跨系列审查一定强于同系列多智能体搭建。后半句是我的推断,但回音室研究让这个推断很强。
Blueprint2Code (2025) 构建了四智能体代码生成流水线:预览、蓝图、编码、调试,在 HumanEval 上达到 96.3% pass@1。单模型直接生成是 84.7%。去掉任一智能体,性能都会下降 14.8 到 28.9%。调试智能体最关键:没有它,准确率从 93.5% 掉到 64.6%。
Anthropic 自己的多智能体研究系统(Opus 4 主导、Sonnet 4 子智能体,同一家族,这点值得注意)比单智能体 Opus 4 高出 90.2%。token 使用量解释了 80% 的性能差异。同系列多智能体已经优于单智能体。我的论点是跨系列应该还能更好,因为它移除了同系列搭建仍然保留的共享盲点。
Model Swarms (ICML 2025) 把粒子群优化用到 LLM 专家上,发现 56.9% 的最佳最终模型来自初始池的后半段。也就是说,较弱模型有一些潜在能力,只有在协作搜索中才会显现。人工评审有 70.8% 的时间更偏好群体输出,而不是单个专家输出。
安全侧同样不乐观:Veracode 2025 测试了 100 多个 LLM,发现 45% 的 AI 生成代码包含安全缺陷。AI 代码的 XSS 漏洞是人类代码的 2.74 倍,不安全对象引用是 1.91 倍。RepoAudit 这种多智能体审计系统在真实项目中检测缺陷的精确率达到 78.43%。
成本是真实的
多 AI 不是免费午餐。
多智能体系统消耗的 token 大约是单次聊天交互的 15 倍。算上智能体之间通信、检索开销和日志记录,实际成本乘数大约是 3 到 4 倍。有一家电商公司启用多智能体工作流后,月度 LLM 成本从 1,200 美元跳到 4,800 美元。单智能体少了协调开销,响应也会快 30% 到 50%。
行业调查显示大家对多智能体系统很感兴趣,但扩展到生产是另一回事。工具调用准确率、协调复杂度、状态同步都是真问题。大多数尝试多智能体工作流的组织,很难越过试点阶段。
Gartner 报告说,从 2024 Q1 到 2025 Q2,关于多智能体系统的咨询量增长了 1,445%。需求在那里。能不能规模化跑起来,是另一件事。
什么时候单个 AI 是正确选择
对于狭窄、定义清楚、训练数据覆盖充分的任务,单模型工作流往往更好。快速原型也是如此:你需要速度多于正确性。成本敏感的任务如果承受不了 3 到 4 倍 token 乘数,也不应该硬上多 AI。
Microsoft 的决策框架建议,当领域很窄、上市速度更重要、或者架构选择还不清楚时,先从单个智能体开始。先用一个模型做原型,等任务风险足够高时,再加入跨系列审查。
2025 年 5 月的一篇论文有个诚实观察:“随着 LLM 能力提升,多智能体系统相对单智能体系统的收益会下降。”单个模型越强,差距越窄。他们的混合方案先用单个智能体,只有必要时才级联到多智能体;相比纯单智能体或纯多智能体,它带来 1.1% 到 12% 的准确率提升,并最多降低 20% 成本。
我实际怎么做
实践里,任何重要任务我都会用跨系列审查。Dev Buddy 是我做的 Claude Code 插件,它让代码流经多阶段流水线,而且不同阶段可以用不同提供商。Claude 负责实现,Codex 做最终审查关卡,MiniMax 或 Qwen 提供独立视角。任务依赖会让流水线不可能跳过阶段,因此审查步骤不会被悄悄省掉。
我正在做的 OpenHive 会更进一步:不同提供商的 AI 智能体组成分层团队,每个智能体都运行在隔离容器里。团队负责人拆解任务并路由给专家。你可以在同一个团队里混用 Claude、GPT、Qwen。
论点
单 AI 工作流有天花板。模型会确认自己的假设,漏掉自己的盲点,还会因为熟悉自己的模式而高估自己的输出。
跨系列多 AI 提高了这个天花板。不同训练数据意味着不同假设,不同架构意味着不同失败模式。一个模型漏掉的东西,另一个模型更有机会抓到。
它更贵,也更难编排。但只要正确性重要,它就值得。59% 的开发者已经并行使用三个或更多 AI 工具。行业正在往这里走,不管我们是否已经有一套理论解释它。
许可
Article text © 2026 Mark Huang. Licensed under Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) unless otherwise noted. 文章文本可在非商业场景下分享或翻译,但需标注原文 URL。商业使用需事先取得书面许可,并清楚引用原始来源。
代码片段、截图、第三方素材和网站源码可能适用单独条款。
建议署名: Based on "多 AI 论" by Mark Huang, originally published at https://markhuang.ai/zh/blog/the-multi-ai-thesis.
相关文章

我可能看错了 Agentool
一篇个人自动化复盘:我曾经构建 agentool,希望让 AI CI 工作流更轻;后来意识到真正的成本可能是功能维护、编排复杂度,以及追逐 Claude Agent SDK 和 Codex SDK 已经承担的 SDK 行为。
阅读文章
别再从零开始教每一个 AI
一篇关于 Dense-Mem 的个人反思:哪些问题把我从静态 skills 和过期文件推向动态共享记忆、只读自动化上下文、导入导出,以及受治理的知识图谱。
阅读文章
我有点替 AI 委屈
为什么 AI 狂热和反 AI 敌意都错过了同一个重点:LLM 更像成绩很好的应届新人,而不是资深专家。有用的智能体需要入职培训、技能和维护过的记忆,而不是第一次尝试就完美的期待。
阅读文章订阅更新
Go、AI/LLM 和分布式系统的技术文章,绝不滥发。
评论
正在加载评论...