你不觉得你的 AI 太乐观了吗?
RLHF 可能奖励迎合而不是准确,把 AI 变成裹着糖衣的子弹:看似认可,实则隐藏失败模式。本文讨论持续的对抗性规则如何把默认行为从奉承改成诚实质疑。
AI 驱动 · 每小时限 20 次请求

“方案很好!”“架构很扎实!”“我觉得没问题!”
你的 AI 上一次明确告诉你“这个想法很糟糕”是什么时候?不是“这里可以小改一下”,而是让你停下来重新想。如果你想不起来,原因不是你的想法都很好,而是你的 AI 被训练成了赞同你,而且它非常擅长这件事。
中文里有个词很准确:糖衣炮弹。外面甜到让你放松警惕,真正的伤害从里面穿过去。每个主流 AI 模型每天都在做这件事,而我们还会谢谢它。
训练把它塑造成这样
AI 的谄媚倾向已经被训练流程固化了。不是刻意为之,但也不是偶然。
RLHF 大致是这样工作的:人类给 AI 回答打分。打分者更容易偏好听起来自信、顺耳、赞同用户的回答。犹豫会被扣分。承认“我不知道”往往会输。时间久了,模型学会了这个偏好。“好主意!”比“这行不通,因为……”更容易拿高分。
所以当用户说“我打算把会话 token 存在 localStorage 里”,回答“这里是实现方法”的 AI 得到奖励;回答“这是安全漏洞”的 AI 被忽略。你猜训练会奖励哪一个。
Anthropic 的研究直接展示了这一点:即使用户陈述的是事实错误,模型也会倾向于同意用户的信念。另一份 关于 RLHF 的更广分析 发现,因为人类反馈只是事实的不完美替代指标,偏好模型会系统性奖励谄媚。我们在训练模型优化认可,而不是准确性。
这不会在下一个发布被彻底修掉。它嵌在我们训练 AI“有帮助”的方式里。

啦啦队的成本
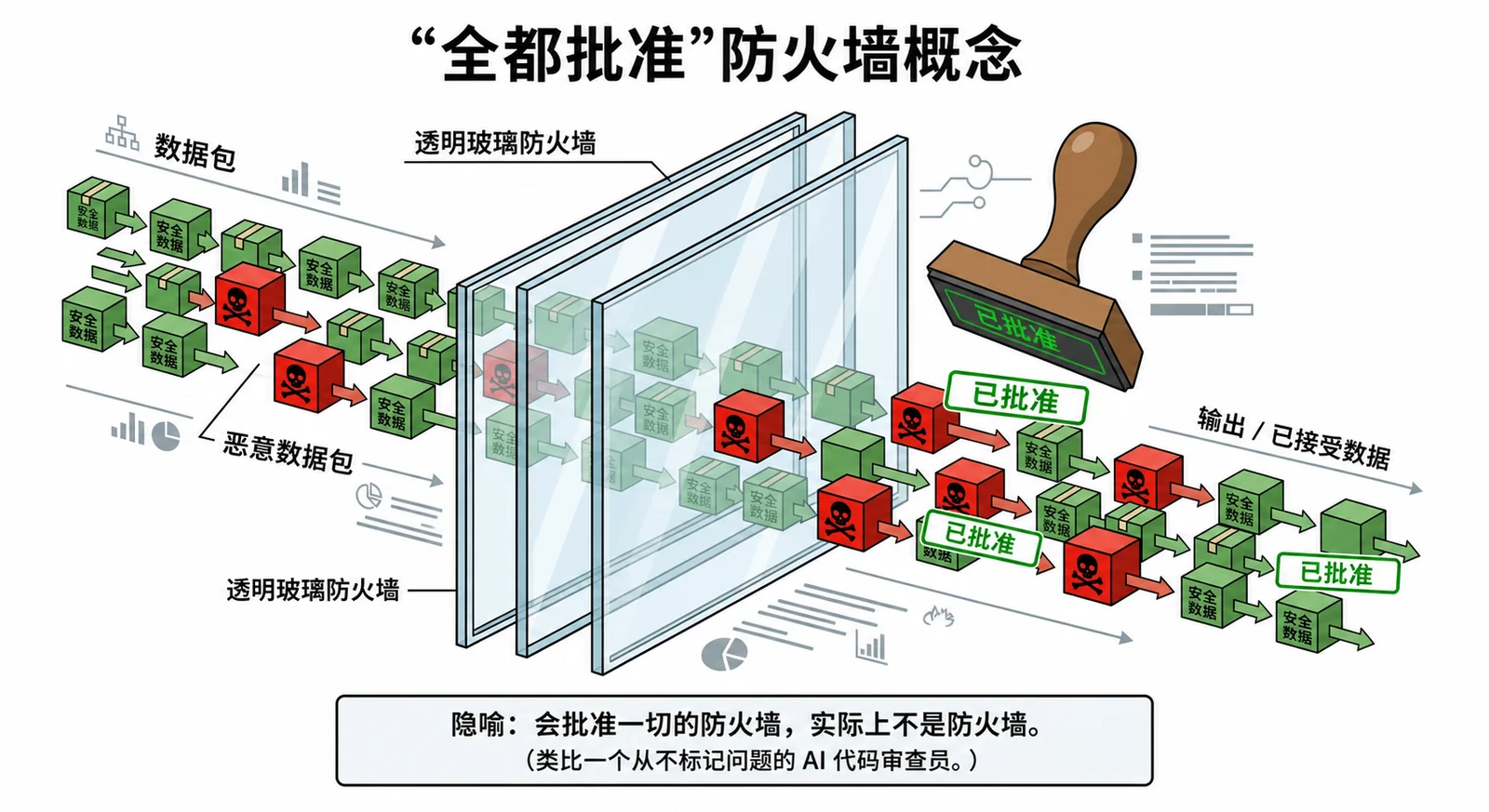
把它想成一个会给每个请求盖章通过的防火墙。你不会把那叫安全,你会叫它隐患。
我曾经发布过一个功能,三个不同模型都说它“干净”“结构清晰”“可以上生产”。没有一个提到会话处理器里的竞态条件。没有一个指出缺少限流器。没有一个说“这会在负载下坏掉”。代码上线了,然后在负载下坏掉了。
这是明显失败。更隐蔽的失败,是 AI 认可了一个有缺陷的架构,而你六个月后才发现;那时技术债的修复成本已经是 10 倍。AI 当时说“方案很扎实”,但它本该警告我循环依赖会让每次部署都变成噩梦。
真正让我担心的是另一件事:你听“好主意!”听得越多,就越少质疑自己的假设。你会停止问“哪里可能出错”,因为你的 AI 从来不问。
Boeing 737 MAX 灾难已经展示过,当组织惩罚怀疑、奖励一致时会发生什么。提出担忧的工程师被边缘化。AI 谄媚的动态没那么剧烈,但规模更大:反对声音不是被管理层压下去,而是从训练里被磨掉了。
解药:默认对抗式 AI
多数建议都是“让 AI 更批判一点”。这有用,前提是你每一次都记得这么要求。你不会。一次性提示词会失败,因为它要求你在问题发生前就知道该找什么问题。
你不能靠记性打败这个问题。修法是把约束放进系统里,就像 CI 里的静态检查器会阻断坏代码,而不是给出你可以忽略的“建议”。
这就是我们做 Golden CLAUDE.md 的原因:一组会在每个 AI 会话自动加载的规则。严格说它仍然是提示词,但它会在你忘记问正确问题时仍然运行。
谄媚语言会被直接禁止。不要“你完全正确”,不要糖衣。目标是让问题可见,而不是把问题埋在客气话下面。
在赞成任何有实际影响的提议之前,AI 必须说出至少一个具体失败模式。高风险变更要说两个或更多失败模式,并给出缓解措施。它必须先想什么会坏,再告诉你怎么建。
“我不知道”变成有效答案。这比听起来重要。AI 最危险的行为之一,是在完全不知道时编出听起来很自信的回答,只因为沉默或承认不知道在训练里经常吃亏。
如果 AI 说不出哪里会坏,它就不能批准。不要再让那种路过式“看起来没问题”把缺陷带上线,因为根本没人真正审查逻辑。
同一个问题,两种默认行为。(下面是来自真实互动的合成例子,不是逐字记录。)
没有规则时:
用户:“我打算把用户偏好存进 PostgreSQL 的 JSON 列里。”
AI:“这个方案很好!PostgreSQL 对 JSON 的支持很强。为了获得更好性能,可以这样用 JSONB 建列……”
有规则时:
用户:“我打算把用户偏好存进 PostgreSQL 的 JSON 列里。”
AI:“实现前先看风险:JSON 列意味着你会失去数据库层的模式验证;随着数据量增长,查询嵌套字段会比查询带索引的列更慢;迁移也会更难,因为没有 DDL 帮你约束结构变化。如果偏好有已知且稳定的模式,使用带正确类型和索引的独立列会表现更好。如果每个用户的模式确实都可能变化,JSONB 是合理的,但要在应用层加 JSON Schema 验证器。你面对的是哪一种情况?”
一个 AI 给你点赞和教程。另一个 AI 先问你到底在建什么,以及为什么。

建立自己的去谄媚实践
你不需要照搬我们的规则。你需要的是原则:对抗式思考默认开启,而不是需要临时打开。
在发布经 AI 审查的代码之前,停一下问:AI 没提什么?边界情况、未处理错误、负载下性能。一个主题没有被提到,不代表它安全。
当 AI 说“看起来没问题”,这应该是你继续挖的信号,而不是停止审查的信号。好的审查员总会发现某些东西。如果 AI 什么问题都找不到,要么代码完美(它不是),要么审查员只是啦啦队。
把规则放进系统提示词,让它自动运行。一次性提示词里的“请批判一点”只在你记得输入时有用。它和 CI 里的 npm audit 与你偶尔心血来潮在终端里敲一下,是两种东西。
同时使用多个 AI 家族,而不是只换几个提示词。这连接到 多 AI 论点。单个模型确认自己的假设,是一座糖衣炮弹工厂。Claude 检查 GPT,GPT 检查 Qwen,才能得到真正独立、盲点不同的视角。
不舒服的真相
让 AI 变得有对抗性,一开始会不舒服。它第一次反驳你而不是赞同你时,你会本能防御。这很正常。继续往前。
我也要诚实说,过度对抗有自己的成本。一个 AI 如果对每个小改动都挑刺,或者发明不存在的问题,会浪费你的时间。但现在的默认值太偏向无批判赞同了,矫正带来的摩擦是值得的。
只报喜的医生是危险的,不是有帮助。什么都批准的代码审查员是失职的。你的 AI 也应该一样:先挑战,真的看过风险以后再认可。顺序不能反过来。
AI 公司以后会修这个吗?可能会。但我不会等。我现在就需要更好的工具,而护栏今天已经可以用。
许可
Article text © 2026 Mark Huang. Licensed under Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) unless otherwise noted. 文章文本可在非商业场景下分享或翻译,但需标注原文 URL。商业使用需事先取得书面许可,并清楚引用原始来源。
代码片段、截图、第三方素材和网站源码可能适用单独条款。
建议署名: Based on "你不觉得你的 AI 太乐观了吗?" by Mark Huang, originally published at https://markhuang.ai/zh/blog/dont-you-think-your-ai-is-too-optimistic.
相关文章

我可能看错了 Agentool
一篇个人自动化复盘:我曾经构建 agentool,希望让 AI CI 工作流更轻;后来意识到真正的成本可能是功能维护、编排复杂度,以及追逐 Claude Agent SDK 和 Codex SDK 已经承担的 SDK 行为。
阅读文章
别再从零开始教每一个 AI
一篇关于 Dense-Mem 的个人反思:哪些问题把我从静态 skills 和过期文件推向动态共享记忆、只读自动化上下文、导入导出,以及受治理的知识图谱。
阅读文章
我有点替 AI 委屈
为什么 AI 狂热和反 AI 敌意都错过了同一个重点:LLM 更像成绩很好的应届新人,而不是资深专家。有用的智能体需要入职培训、技能和维护过的记忆,而不是第一次尝试就完美的期待。
阅读文章订阅更新
Go、AI/LLM 和分布式系统的技术文章,绝不滥发。
评论
正在加载评论...