多 AI 系统
围绕跨模型家族的多 AI、集成评审、AI 编码流水线和模型单一化风险的整理路径。
快速回答
多 AI 系统使用不止一个模型、模型家族或专门助手,目的是减少盲点、独立评审工作,并按能力路由任务,而不是把一个模型当成唯一裁判。
适合读者
如果你正在设计 AI 编码工作流、独立评审环节或跨模型家族策略,可以从这里开始。
它回答的问题
- 为什么高风险工作不能只依赖一个 AI 模型?
- 跨模型家族评审如何降低相关性错误?
- 什么时候多 AI 的额外成本是值得的?
- 团队应该如何用独立评审构建 AI 编码流水线?
文章

三个臭皮匠,顶个诸葛亮:让便宜模型协同工作
一堂来自中文俗语“三个臭皮匠,顶个诸葛亮”的个人 AI 架构课:为什么便宜模型会被巨大提示词压垮,以及聚焦的专家会话、编排、综合和温度控制如何让它们变得有用。

1+1 假说:能否把编程问题拆到任何 LLM 都能做?
每个 LLM 都会算 100×100,每个编程 LLM 都能重命名变量。但可靠性从哪里开始断裂?工程化 harness 能不能把边界往前推?本文讨论剩余解空间熵、测试先行契约、分层防御架构,以及为什么盲目共识会失败,而验证式搜索有效。

没有意图的自动化,只是更快的混乱
三套失败的流水线架构,一次关于反压的教训,以及最终让多 AI 氛围编程跑起来的 UAT 门。本文复盘什么坏了、什么留下来,以及为什么知道自己想要什么比工具本身更重要。
为什么一个 AI 永远不够
医学、法律、科学和金融等高风险行业都要求独立复核,AI 却常常跳过这一步。37% 的企业已经使用 5 个以上模型,但多数仍是临时拼接。跨模型家族多 AI 系列第一章。
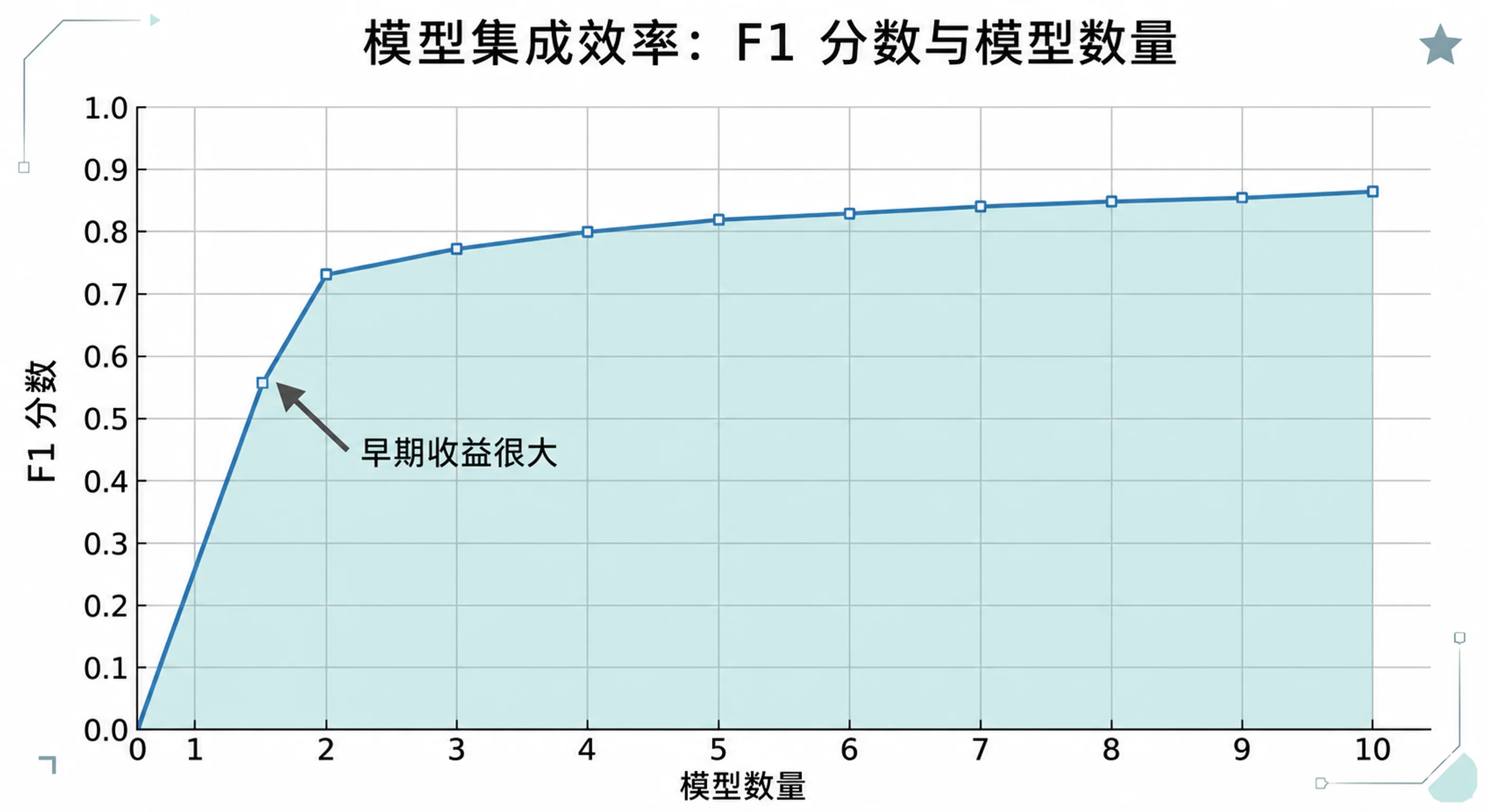
集成智能背后的科学
群体智慧遇上 AI:多样化 LLM 集成超过 67% 的单一模型,F1 分数从 0.55 提升到 0.80 以上,而 56.9% 的最佳方案来自最弱模型。跨模型家族多 AI 系列第二章。
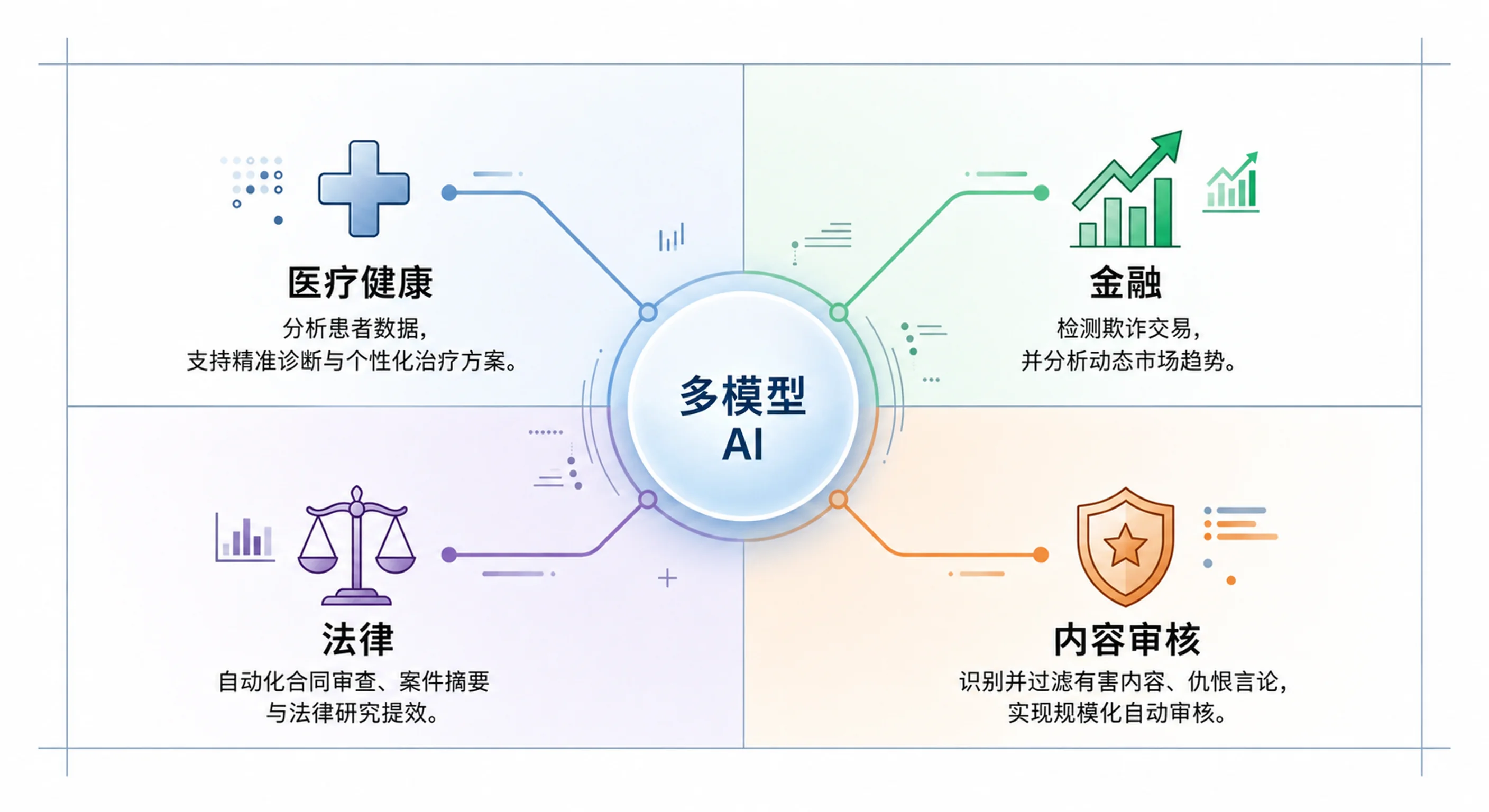
行业证据:医疗、金融、法律以及更多场景
多模型 AI 已经进入医疗诊断、金融风险管理、法律分析和内容审核的主流实践。本文整理四个行业的证据,以及它们对跨模型家族 AI 采用的意义。跨模型家族多 AI 系列第三章。
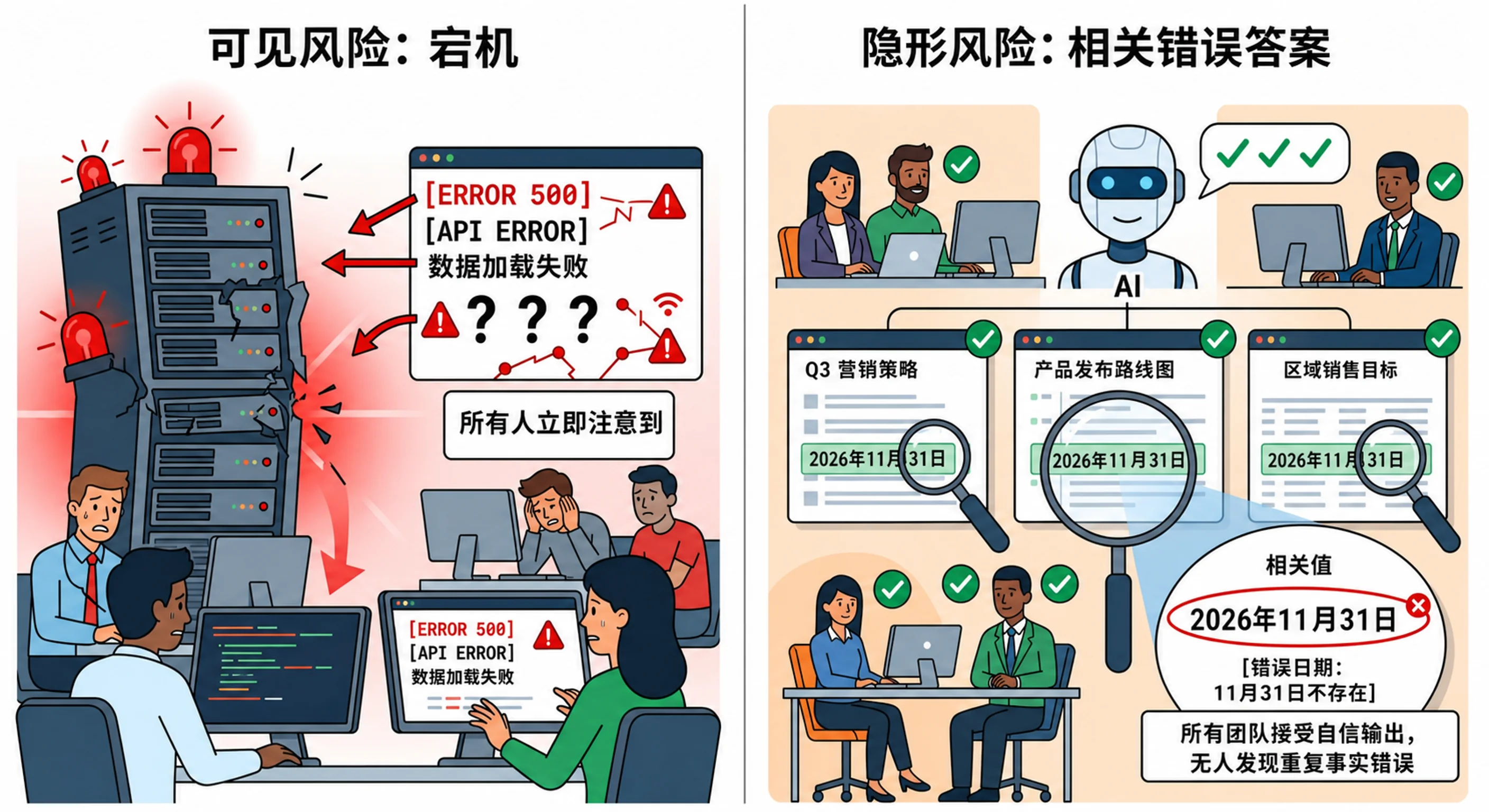
模型单一化风险:当所有 AI 都同意同一个错误答案
依赖单一 AI 的危险不只是宕机,而是相关性错误:答案错了,却没有任何系统反驳。当每个团队使用同一个模型家族,同样的盲点会安静地扩散。跨模型家族多 AI 系列第四章。
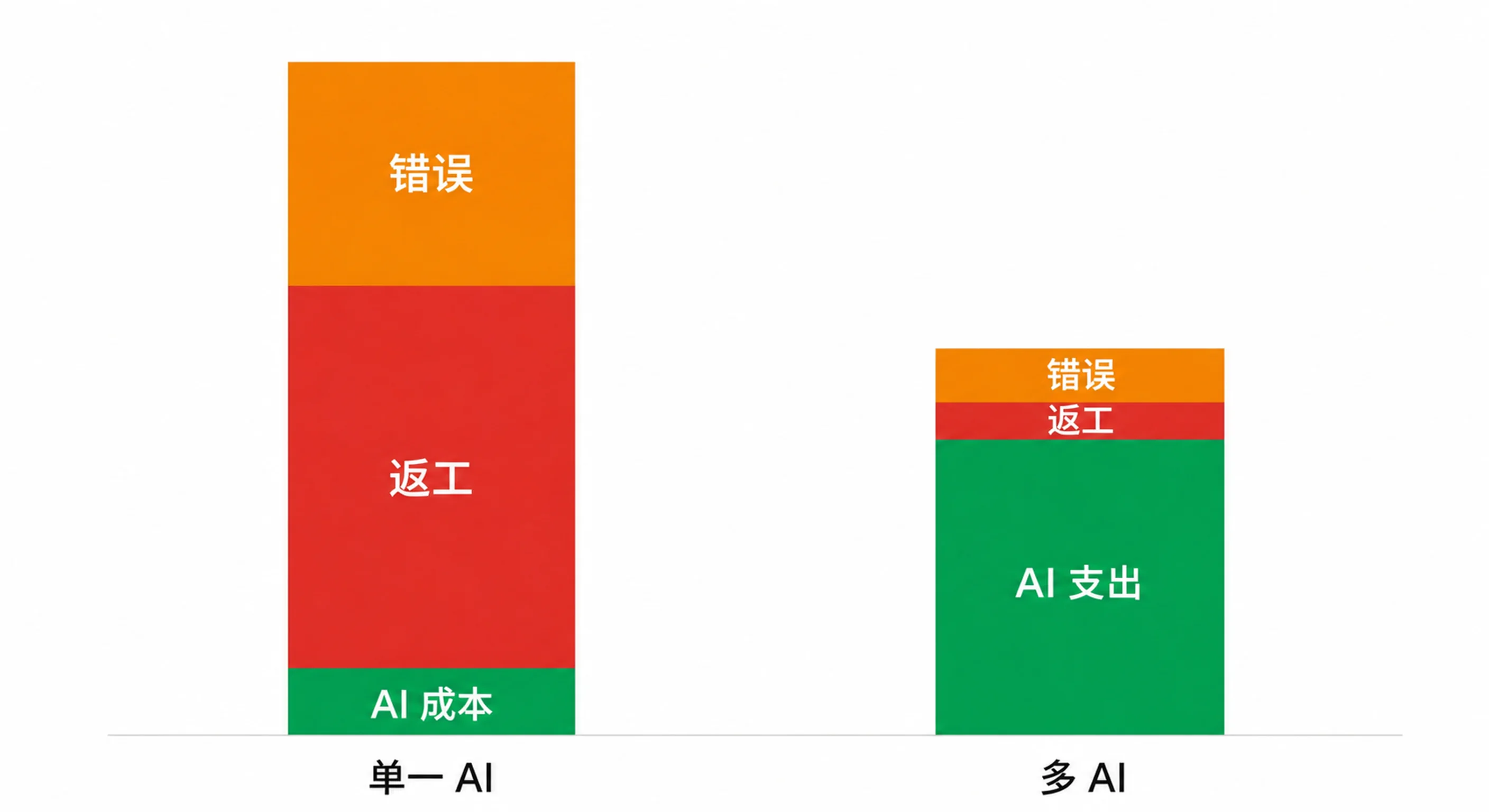
成本问题:什么时候多 AI 能收回成本
多 AI 的 token 成本可能高出 3 到 4 倍,但组织会把 40% 的 AI 生产力收益浪费在返工上。本文讨论执行顺序、按任务缩放,以及成熟与不成熟 AI 实践之间 21 倍 ROI 差距。跨模型家族多 AI 系列第五章。
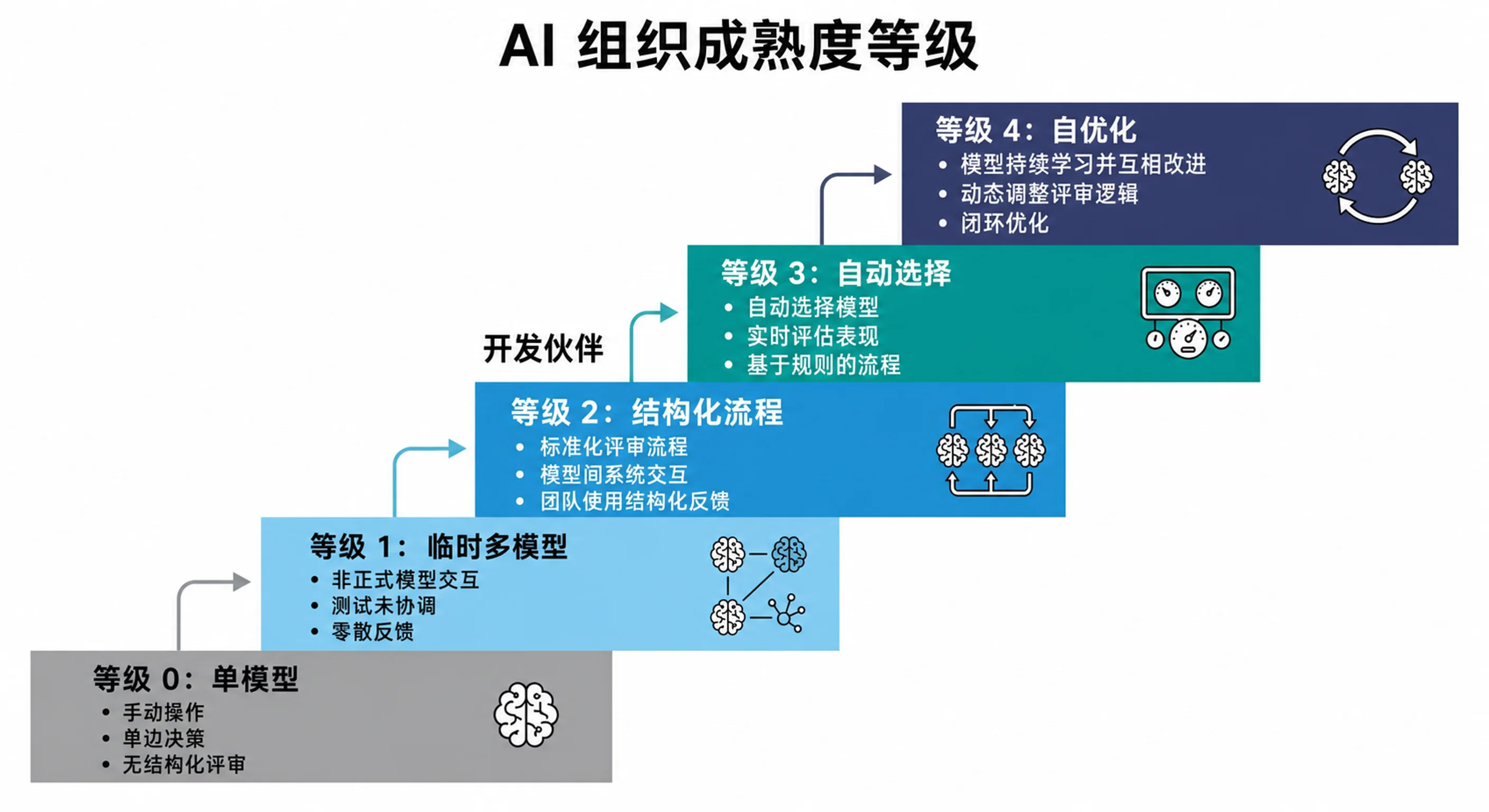
下一段路:建立跨模型家族的 AI 实践
从单一模型到自优化的五级成熟度模型,面向个人、团队和企业的可执行下一步,以及对仍需补齐的证据缺口的坦诚整理。跨模型家族多 AI 系列第六章。

多 AI 论
LLM 会在超过 90% 的情况下确认自己的答案,对自身错误还有 64.5% 的盲区率。跨模型家族的多 AI 流水线,让 Claude 评审 GPT、GPT 评审 Qwen,能打破自我评审的天花板。本文讨论研究、成本和真正有效的做法。

Dev Buddy:为 Claude Code 构建多 AI 开发流水线
一篇面向实践的 Dev Buddy 指南:这个开源 Claude Code 插件通过结构化开发流水线编排多个 AI 模型,支持基于任务的约束、并行专家分析,以及自动修复后重新评审的循环。
项目
agentool
Vercel AI SDK tool suite with production-ready agent tools for file operations, shell execution, code search, web fetching, memory, and context compaction.
GitVibe
Maintainer-gated AI development pipeline for GitHub issues, discussions, labels, workflows, branches, and pull requests.